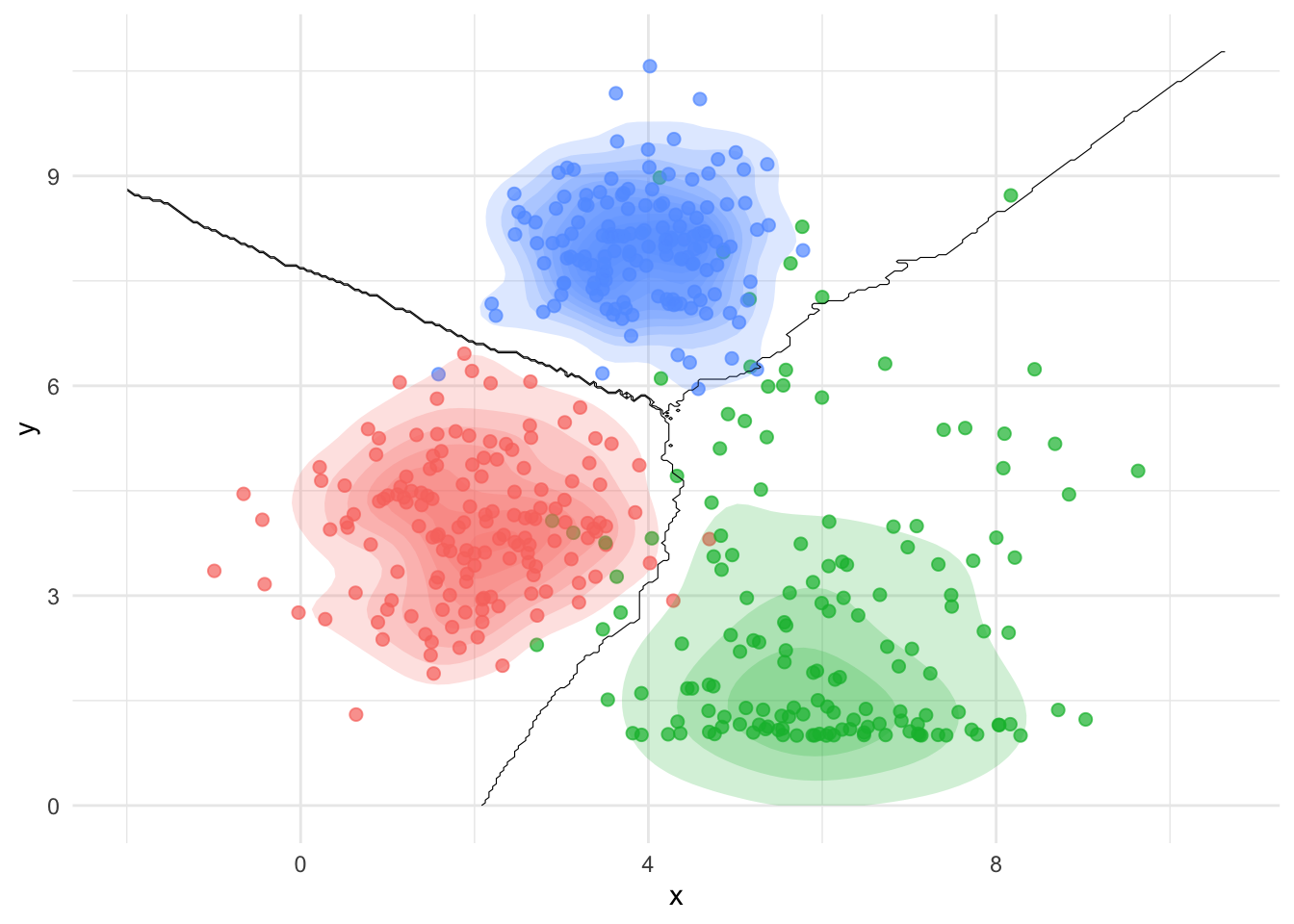
library(ggplot2)library(MASS)library(class) # Für k-NN Klassifikation# Synthetische Daten erzeugenset.seed(42)n <-150group1 <-data.frame(x =rnorm(n, mean =2, sd =1), y =rnorm(n, mean =4, sd =1), group ="A")group2 <-data.frame(x =rnorm(n, mean =6, sd =1.5), y =sin(rnorm(n, mean =5, sd =1)) *4+5, group ="B")group3 <-data.frame(x =rnorm(n, mean =4, sd =0.8), y =rnorm(n, mean =8, sd =0.8), group ="C")# Daten kombinierendata <-rbind(group1, group2, group3)# Raster für Entscheidungsgrenzengrid <-expand.grid(x =seq(min(data$x) -1, max(data$x) +1, length =300),y =seq(min(data$y) -1, max(data$y) +1, length =300))# k-NN Klassifikation für nicht-lineare Grenzenknn_pred <-knn(train = data[, 1:2], test = grid, cl = data$group, k =15)grid$pred <- knn_pred# Plotggplot(data, aes(x = x, y = y, color = group)) +geom_point(size =2, alpha =0.7) +# Punktegeom_contour(data = grid, aes(z =as.numeric(pred)), breaks =c(1.5, 2.5), color ="black", linewidth =0.2, linetype ="solid") +# Wilde Grenzenstat_density_2d(aes(fill = group), geom ="polygon", alpha =0.2, color =NA) +# Farbige Dichtekonturentheme_minimal() +theme(legend.position ="none")
Clustering
Eine Clusteranalyse klassifiziert Bezugs/Raumeinheiten auf der Grundlage von Ähnlichkeitsmassen (z.B. Klimatypen, Stadttypen, etc.).
12.1 Schwellenwertanalyse
Eine einfachste Methode zur Klassifizierung ist die Schwellenwertanalyse. Diese erfordert theoretische oder empirische Kenntnisse über die zu klassifizierenden Objekte und nutzt subjektie Schwellenwerte.
Beispielanwendung:
Spam-Filterung (Mails über bestimmtem Score als Spam markieren)
Betrugserkennung (Transaktionen mit Anomalie-Score > Schwelle)
Kreditrisikobewertung (Kunden mit Score < Grenzwert als risikoreich einstufen)
12.2 Nicht-hierarchische Verfahren
Werte so lange immer wieder auf die Cluster verteilt, bis die Summe der Abstände von zugehörigen Cluster-Mitten minimal ist
Vorteil: Werte werden flexibel auf Cluster verteilt
Nachteil: Anzahl der Cluster muss a-priori vorgegeben werden
Beispielanwendung:
Kundensegmentierung im Marketing
Mustererkennung in Bildverarbeitung
Gruppierung von News-Artikeln nach Themen
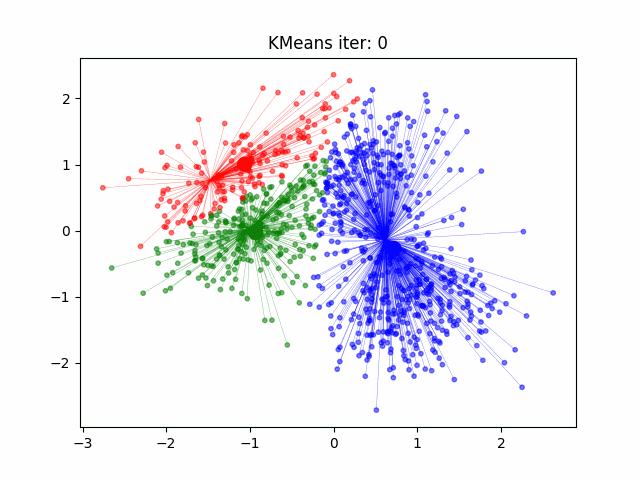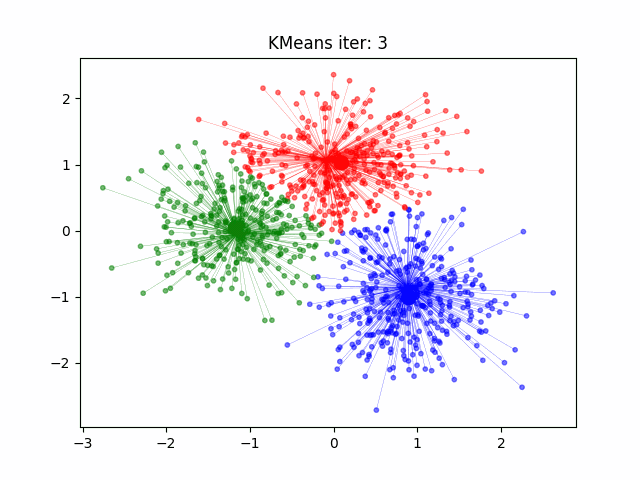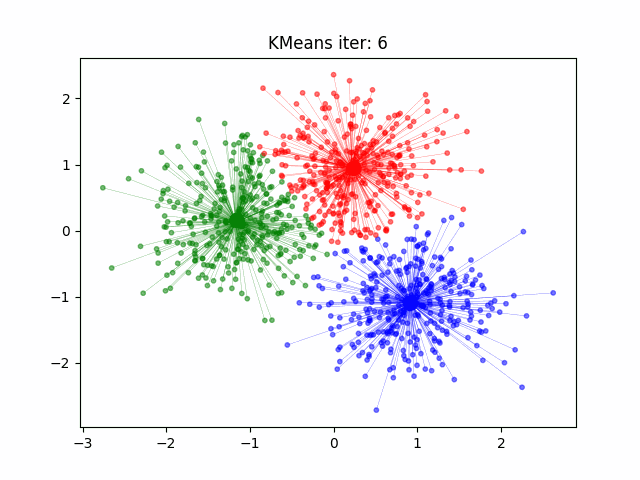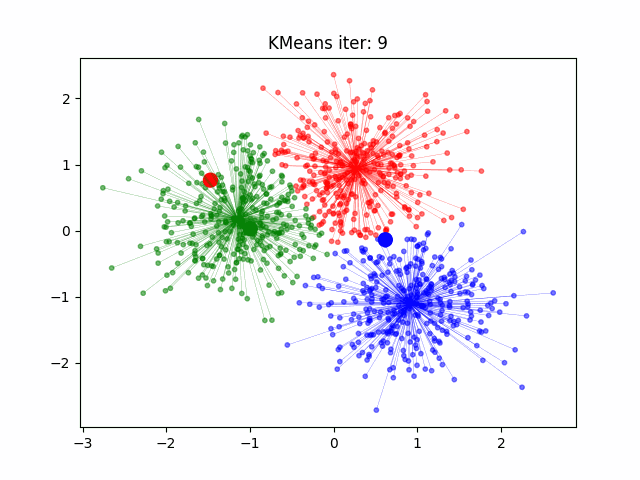
12.2.1 k-Means
K-Means
Initialisierung: \(k\) Clusterzentren auf \(k\) zufällige, aber unterschiedliche Positionen im \(p\)-dimensionalen Raum setzen, möglichst so dass die Abstände zwischen initialen Clusterzentren maximal sind. Jedem Clusterzentrum wird eine eindeutige Klassennummer (1 bis \(k\)) zugewiesen.
Klassifizierung: Finde für jeden Datenpunkt das nächste Clusterzentrum und weise dem Datenpunkt die Klassennummer dieses Clusterzentrums zu.
Clusterzentren berechnen: Berechne die Position der Clusterzentren neu, in dem alle Datenpunkte die zu einer bestimmten Klasse gehören gemittelt werden.
Iteration: Wiederholung ab Schritt 2, bis die Klassifizierung stabil ist
Code
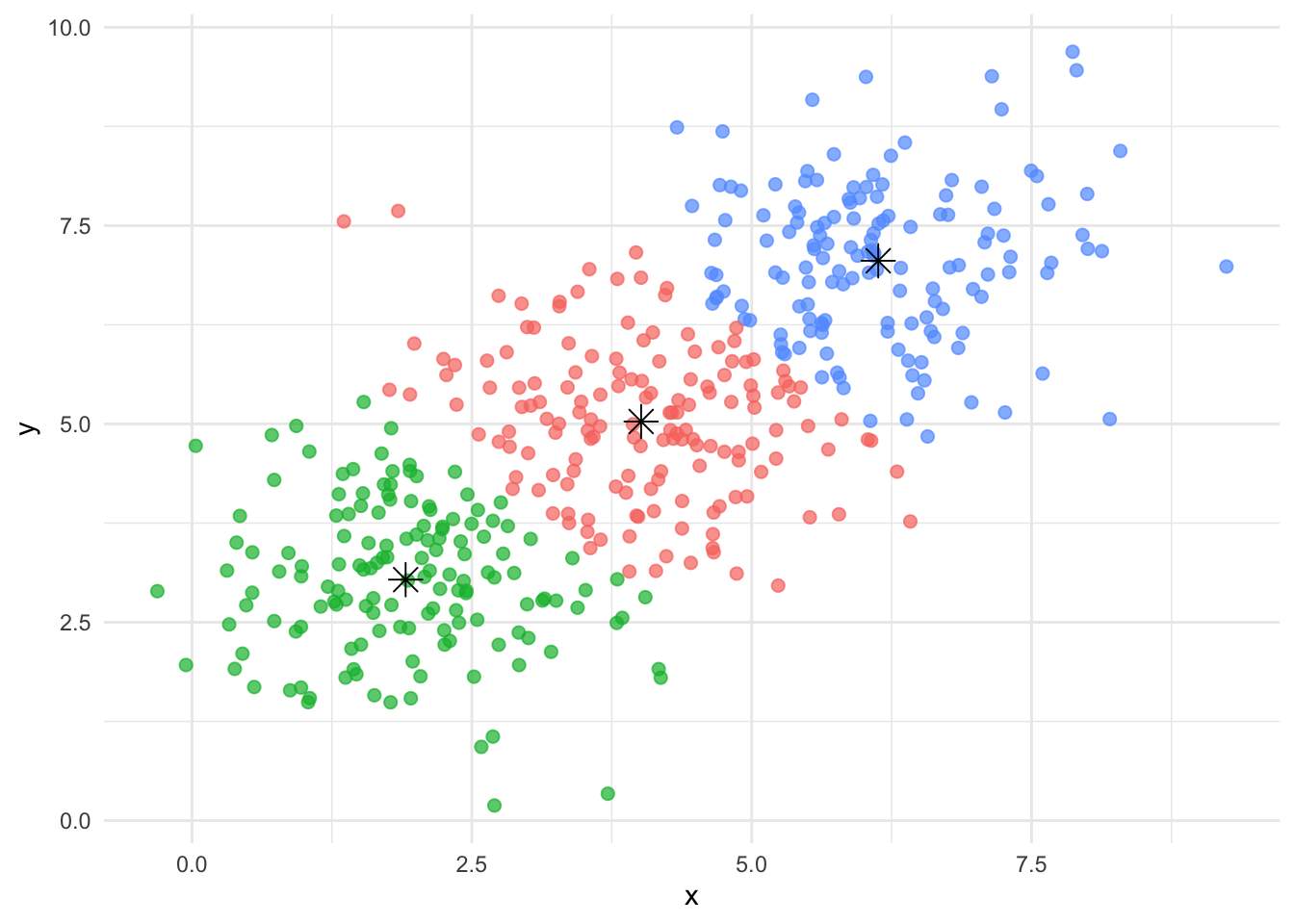
library(ggplot2)# Synthetische Daten erzeugenset.seed(123)n <-150data_kmeans <-data.frame(x =c(rnorm(n, mean =2), rnorm(n, mean =6), rnorm(n, mean =4)),y =c(rnorm(n, mean =3), rnorm(n, mean =7), rnorm(n, mean =5)))# K-Means Clusteringkmeans_result <-kmeans(data_kmeans, centers =3)data_kmeans$cluster <-as.factor(kmeans_result$cluster)# Plot für K-Means Clusteringggplot(data_kmeans, aes(x = x, y = y, color = cluster)) +geom_point(size =2, alpha =0.7) +geom_point(data =as.data.frame(kmeans_result$centers), aes(x = x, y = y), color ="black", size =4, shape =8) +# Zentren als Sternetheme_minimal() +theme(legend.position ="none")
K-Means-Clustering mit synthetischen Daten
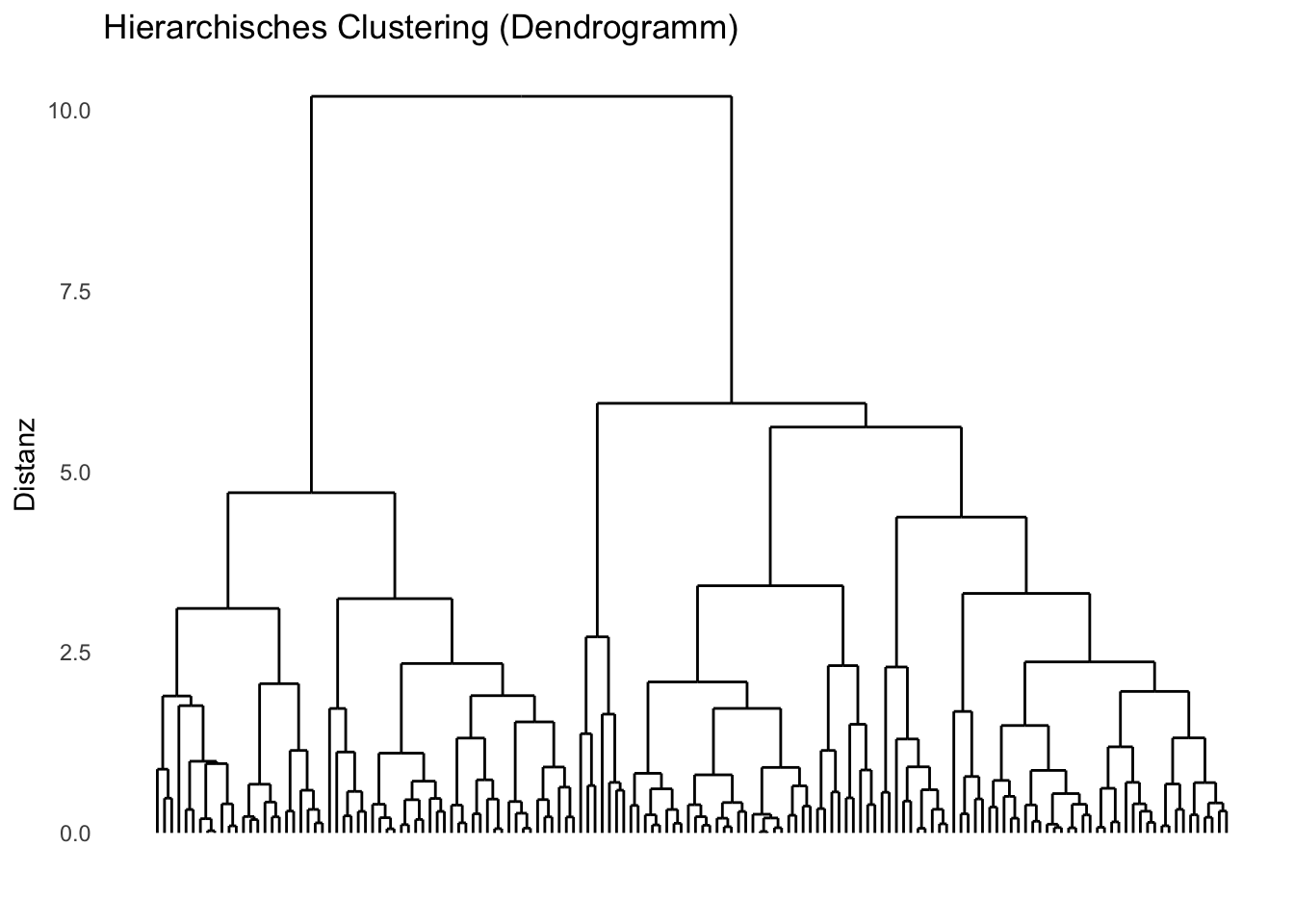
12.3 Hierarchisches Clustering
iterative Vorgehensweise, bei der die Cluster des letzten Schrittes immer weiter zusammengefasst werden
Nachteil: Einmal klassifizierte Werte verbleiben in dem Cluster auch wenn sich die Eigenschaften des Cluster im Laufe der Verfahrensschritte verändern
Vorteil: Anzahl der Cluster muss nicht a-priori vorgegeben werden
Beispielanwendung:
Verwandtschaftsanalyse in der Genetik
Klassifikation von Dokumenten (Taxonomien)
Analyse von Verkehrsströmen in Städten
Code
library(ggdendro)n <-50# Synthetische Daten erzeugendata_hclust <-data.frame(x =c(rnorm(n, mean =1), rnorm(n, mean =5), rnorm(n, mean =3)),y =c(rnorm(n, mean =2), rnorm(n, mean =6), rnorm(n, mean =4)))# Hierarchisches Clusteringdist_matrix <-dist(data_hclust)hclust_result <-hclust(dist_matrix)# Dendrogramm-Daten für ggplotdend_data <-dendro_data(hclust_result, type ="rectangle")# Plot für das Dendrogrammggplot() +geom_segment(data = dend_data$segments, aes(x = x, y = y, xend = xend, yend = yend), color ="black") +theme_minimal() +labs(title ="Hierarchisches Clustering (Dendrogramm)",x ="", y ="Distanz") +theme(axis.text.x =element_blank(),axis.ticks.x =element_blank(),panel.grid =element_blank())