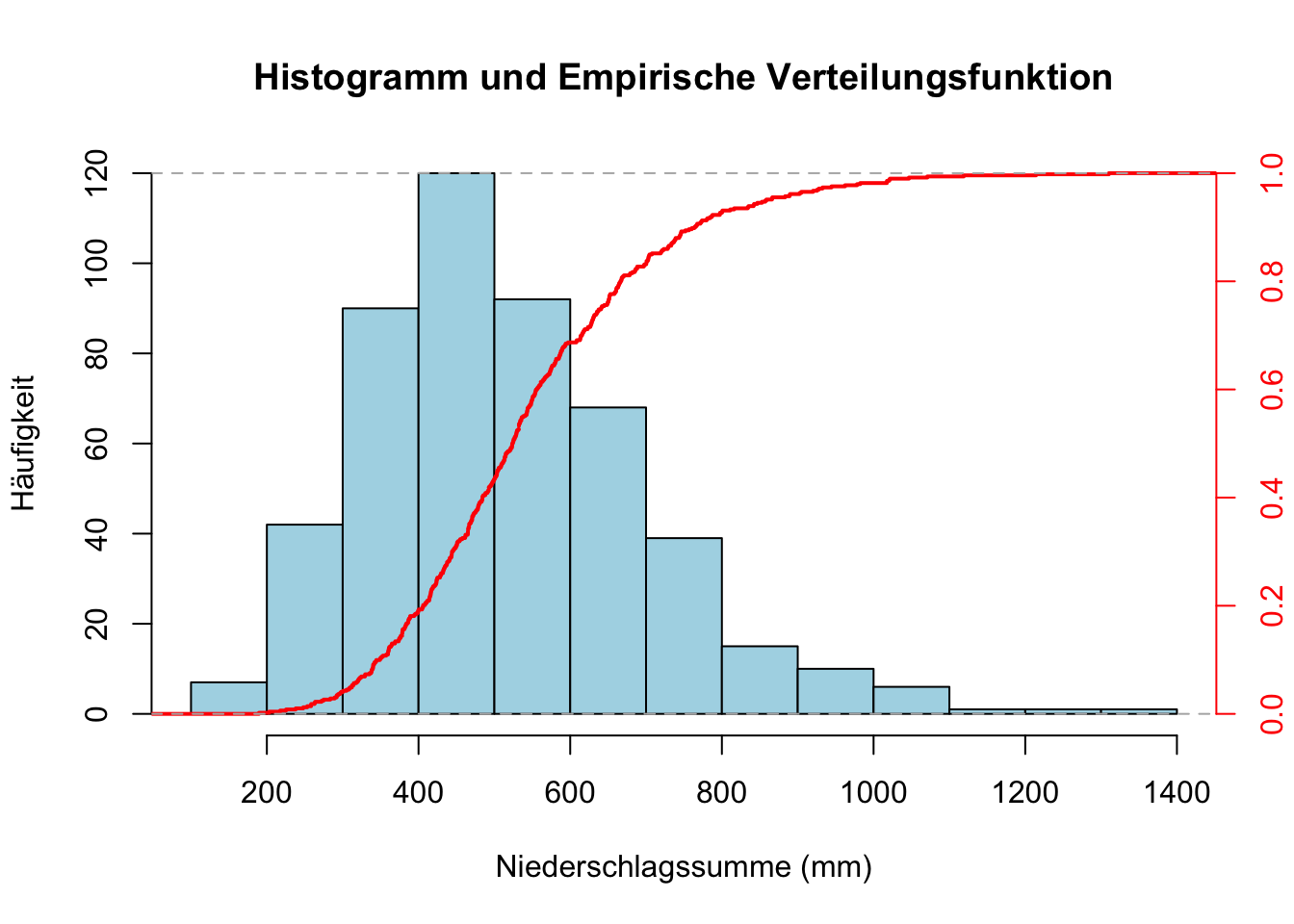
Erstellt mit R das Histogramm und die Verteilungsfunktion des Sommer-Niederschlags am Grossen St. Bernhard (Datei mit Saison-Mittelwerten). Tipp: In R kann die empirische Verteilungsfunktion mit der Funktion ecdf() erzeugt werden.
meteodaten <-read.csv('Data/meteodaten_saison.csv',sep =',',header =TRUE)# Zeichne das Histogramm mit absoluter Häufigkeithist(meteodaten$GrStBernhard_Niederschlagssumme,main ="Histogramm und Empirische Verteilungsfunktion",xlab ="Niederschlagssumme (mm)",ylab ="Häufigkeit",col ="lightblue",freq =TRUE) # Zeigt absolute Häufigkeit# Füge die empirische Verteilungsfunktion hinzupar(new =TRUE) # Erlaube das Zeichnen eines neuen Plots auf der bestehenden Grafikplot(ecdf(meteodaten$GrStBernhard_Niederschlagssumme),axes =FALSE, # Deaktiviere Achsen für den zweiten Plotxlab ="",ylab ="",main ="", # Kein Titel, um Überlappung zu vermeidencol ="red",lwd =2,pch =NA) # Entfernt die Punkte auf der Linie# Füge die rechte y-Achse hinzuaxis(4, col ="red", col.axis ="red") # 4 steht für die rechte Seitemtext("F(x)", side =4, line =3, col ="red") # Beschriftung der rechten y-Achse
Lies aus dem Plot der Verteilungsfunktion ungefähr ab, welcher Niederschlag in 20% der Jahre überschritten wird?
# Zeichne das Histogramm mit absoluter Häufigkeithist(meteodaten$GrStBernhard_Niederschlagssumme,main ="Histogramm und Empirische Verteilungsfunktion",xlab ="Niederschlagssumme (mm)",ylab ="Häufigkeit",col ="lightblue",freq =TRUE) # Zeigt absolute Häufigkeit# Füge die empirische Verteilungsfunktion hinzupar(new =TRUE) # Erlaube das Zeichnen eines neuen Plots auf der bestehenden Grafikplot(ecdf(meteodaten$GrStBernhard_Niederschlagssumme),axes =FALSE, # Deaktiviere Achsen für den zweiten Plotxlab ="",ylab ="",main ="", # Kein Titel, um Überlappung zu vermeidencol ="red",lwd =2,pch =NA) # Entfernt die Punkte auf der Linie# Berechne den Wert, bei dem die Verteilungsfunktion 80% überschreitetniederschlag_80 <-quantile(meteodaten$GrStBernhard_Niederschlagssumme, 0.8)# Füge die rechte y-Achse hinzuaxis(4, col ="red", col.axis ="red") # 4 steht für die rechte Seitemtext("F(x)", side =4, line =3, col ="red") # Beschriftung der rechten y-Achse# Zeichne eine vertikale Linie bei 80%abline(v = niederschlag_80, col ="blue", lty =2) # Vertikale Linie bei 80%-Quantil hinzufügentext(niederschlag_80, 0.5, paste("80%:", round(niederschlag_80, 1), "mm"), col ="blue", pos =4)# Zeichne eine horizontale gestrichelte Linie bei 80%abline(h =0.8, col ="blue", lty =2)
ANTWORT: Die Niederschlagssumme, die in 20% der Jahre überschritten wird, beträgt 647.2 mm.
E.1 Statistische Tests mit Psychologieexperiment
Daten einlesen
psychologieExperiment <-read.table('Data/Psycho_Exp_Ergebnisse2_2024-10-28.csv',sep =',',header =TRUE,na.strings ='999')# Spalten im DataFrame umbenennen (kürzere und schönere Namen)colnames(psychologieExperiment) <-c("Gefuehl_Vor_SelberGutesTun","Gefuehl_Nach_SelberGutesTun","Gefuehl_Vor_AnderenGutesTun","Gefuehl_Nach_AnderenGutesTun")
Gehen wir mal davon aus, dass die Mittelwerte interpretierbar seien. (Nächste Woche lernen wir weitere Test für Verteilungen kennen und Test, wenn die Normalverteilung nicht gegeben ist.) Dann könnten wir untersuchen, wie stark sich die Mittelwerte vor und nach dem Experiment unterscheiden und ob die Unterschiede statistisch signifikant sind.
Stellt nun zunächst die Null- und Alternativhypothesen für beide Experimente (1. sich selber und 2. anderen etwas gutes tun) auf, ob etwas Gutes tun sich auf das Wohlbefinden auswirkt.
H0: Die beiden Mittelwerte sind gleich
HA: Jemandem oder uns selbst etwas Gutes zu tun, hat einen (positiven) Einfluss auf das Wohlbefinden
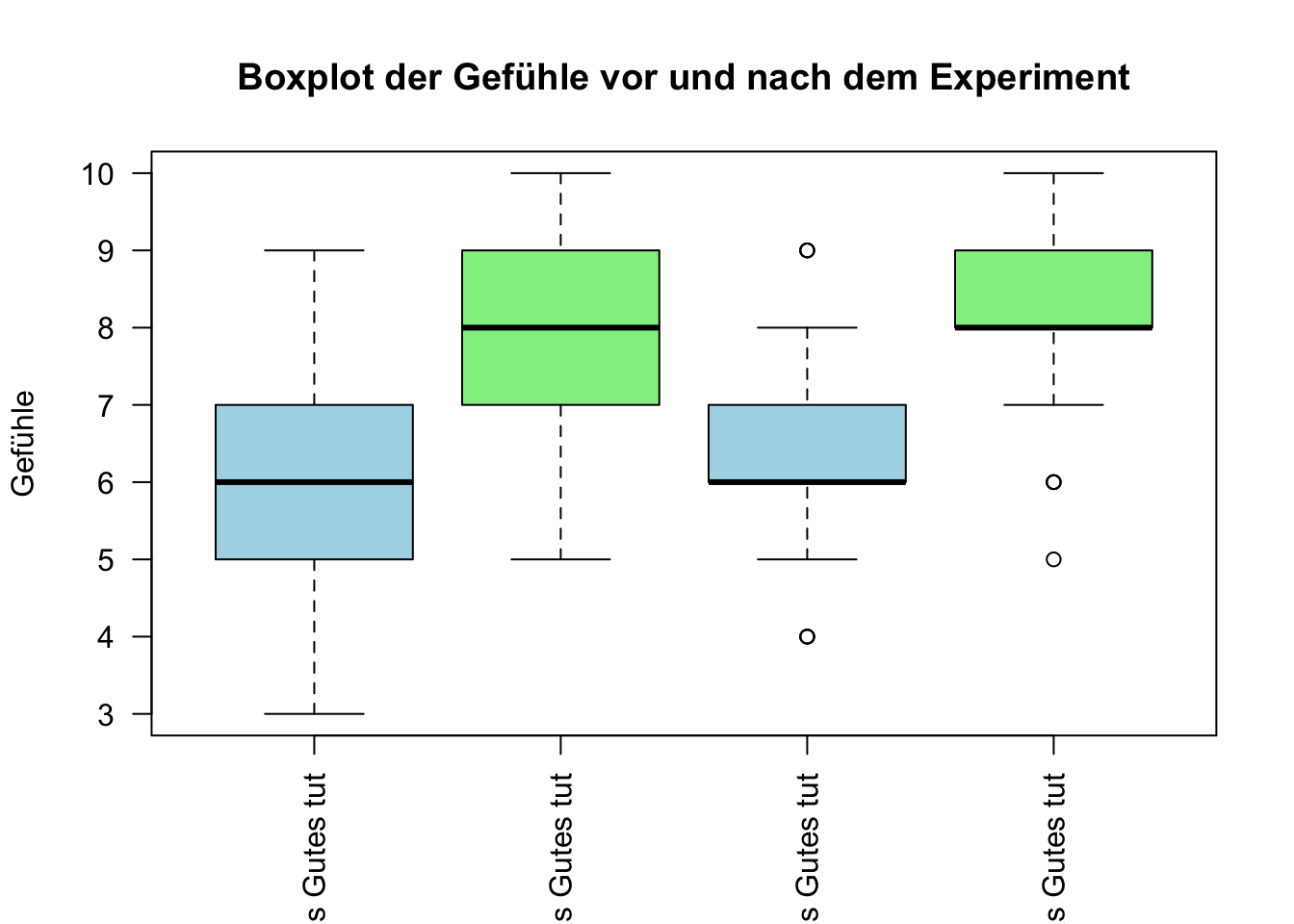
Erstelle einen Boxplot, um die Verteilung der Daten anzusehen und einen ersten Eindruck zu erhalten
boxplot(psychologieExperiment,main ="Boxplot der Gefühle vor und nach dem Experiment",ylab ="Gefühle",col =c("lightblue", "lightgreen"),names =c("Gefühl, vor dem man sich selbst etwas Gutes tut","Gefühl, nach dem man sich selbst etwas Gutes tut","Gefühl, vor dem man jemand anderem etwas Gutes tut","Gefühl, nach dem man jemand anderem etwas Gutes tut"),las =2)
Berechne wie gross die Unterschiede der Mittelwerte sind?
ANTWORT: Beide Effekte sind positiv. Fast identisch grosse Effekte.
Führe nun einen 2-Stichproben T-Test mit R durch. Schau dir mit der Hilfe unter ?t.test die Parameter der t.test Funktion in R an. Wähle entsprechend einen ein- oder zweiseitigen Test, das Konfidenzlevel mit 99% und gehe davon aus, dass die Varianzen beider Stichproben gleich sind. Recherchiere, ob es sich um abhängige oder unabhängige Stichproben handelt. Gibt den entsprechenden Parameter bei der Nutzung der t.test Funktion an.
Paired t-test
data: psychologieExperiment$Gefuehl_Nach_SelberGutesTun and psychologieExperiment$Gefuehl_Vor_SelberGutesTun
t = 9.8012, df = 36, p-value = 5.298e-12
alternative hypothesis: true mean difference is greater than 0
99 percent confidence interval:
1.523537 Inf
sample estimates:
mean difference
2.027027
Paired t-test
data: psychologieExperiment$Gefuehl_Nach_AnderenGutesTun and psychologieExperiment$Gefuehl_Vor_AnderenGutesTun
t = 8.5716, df = 36, p-value = 1.61e-10
alternative hypothesis: true mean difference is greater than 0
99 percent confidence interval:
1.373909 Inf
sample estimates:
mean difference
1.918919
Interpretiere die Ausgabe des Tests (Konfidenzintervalle besprechen wir nächste Woche).
ANTWORT:
Ihr könntest mit einem gleichen t-Test auch testen, ob der Effekt beider Experimente gleich gross ist, d.h. wirkt es sich gleich oder unterschiedlich auf das Befinden aus, ob man sich selbst oder anderen etwas Gutes tut. Wie würdet ihr hierfür vorgehen?
Hypothesen aufstellen
H0: Ob ich anderen oder mir selber tue underscheidet sich nicht in der Auswirkung auf mein Wohlbefinden.
HA: Ob ich anderen oder mir selber tue unterscheidet sich in der Auswirkung auf mein Wohlbefinden.
Paired t-test
data: psychologieExperiment$Gefuehl_Nach_SelberGutesTun - psychologieExperiment$Gefuehl_Vor_SelberGutesTun and psychologieExperiment$Gefuehl_Nach_AnderenGutesTun - psychologieExperiment$Gefuehl_Vor_AnderenGutesTun
t = 0.48727, df = 36, p-value = 0.3145
alternative hypothesis: true mean difference is greater than 0
99 percent confidence interval:
-0.4320254 Inf
sample estimates:
mean difference
0.1081081
Interpretation aller ausgegebenen Ergebnisse der R t-test() Funktion.
ANTWORT:
Mit dem t-Wert von ca. 0.5 und einem p-Wert von ca. 0.3 können wir die Nullhypothese nicht ablehnen. Es gibt keinen statistisch signifikanten Unterschied zwischen den beiden Experimenten.
E.2 Chi^2 Verteilungstest zu Würfelexperiment
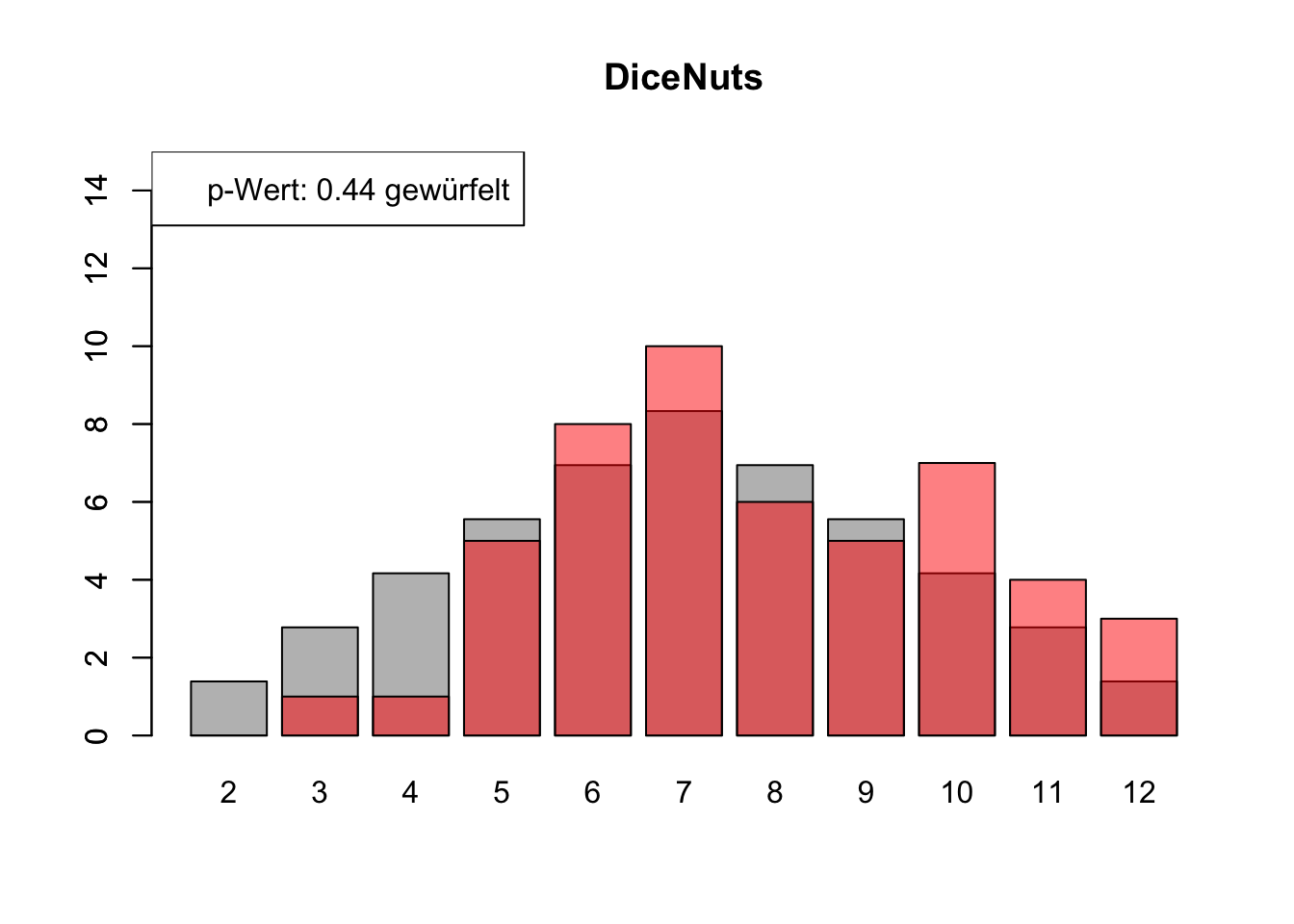
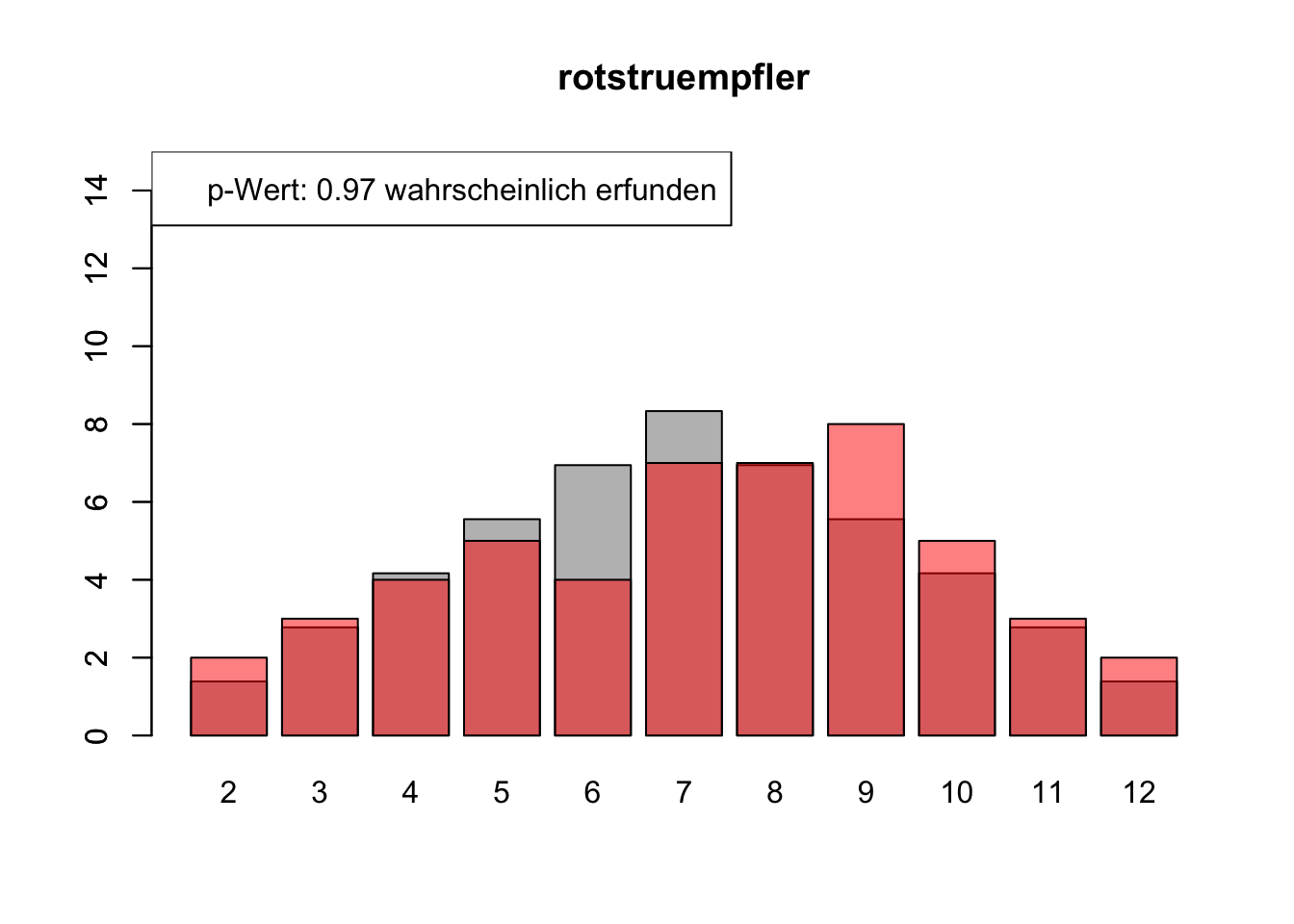
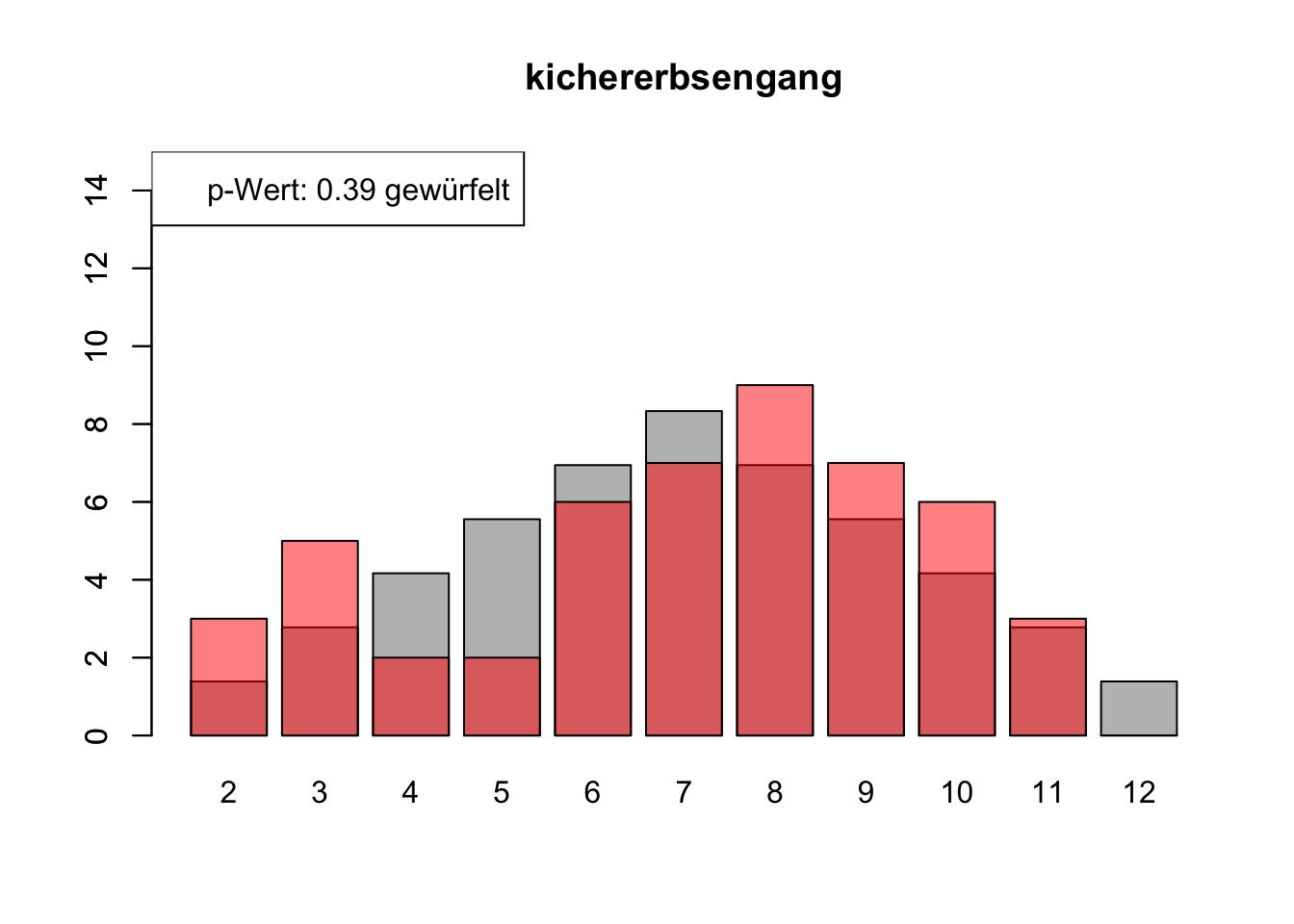
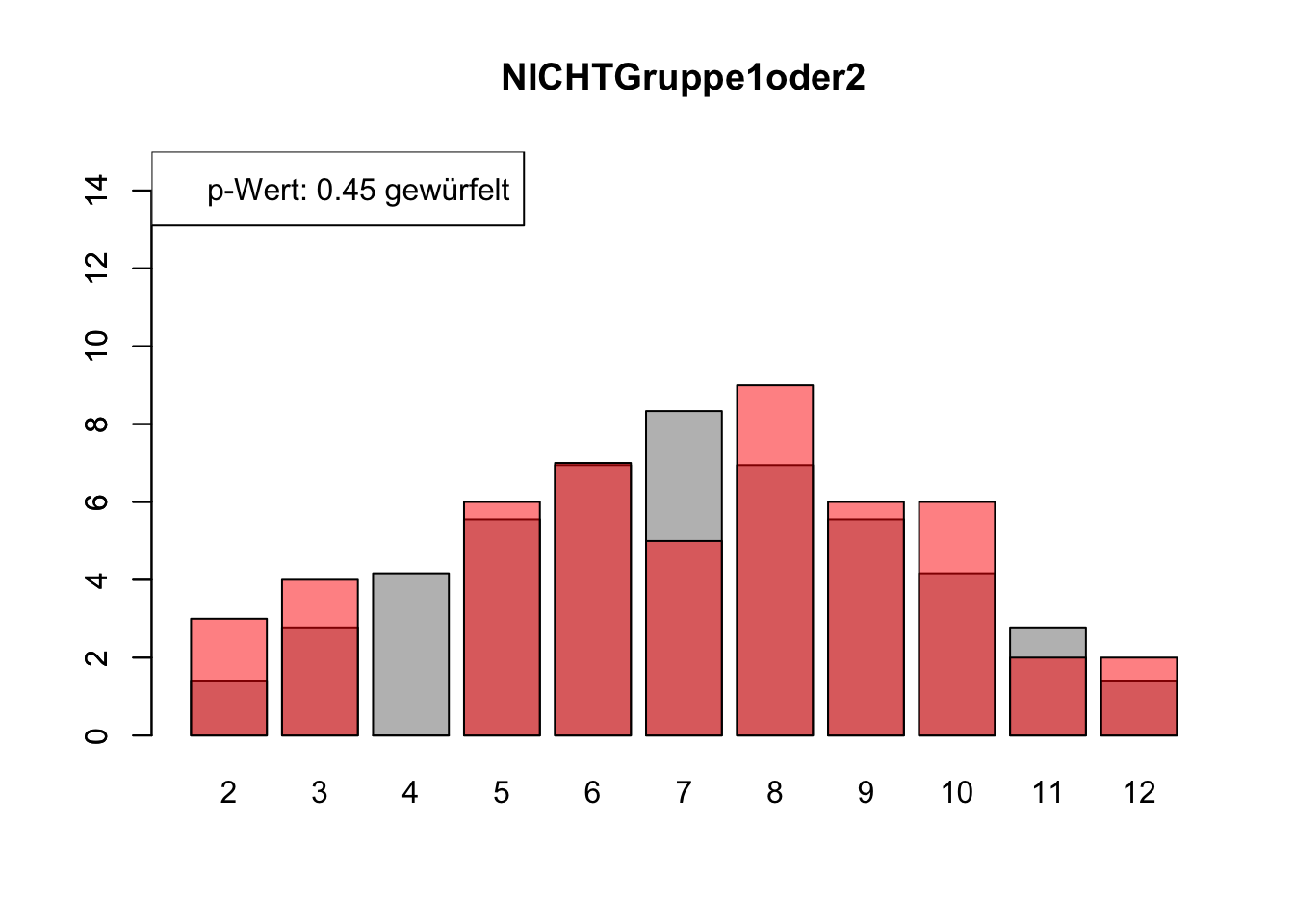
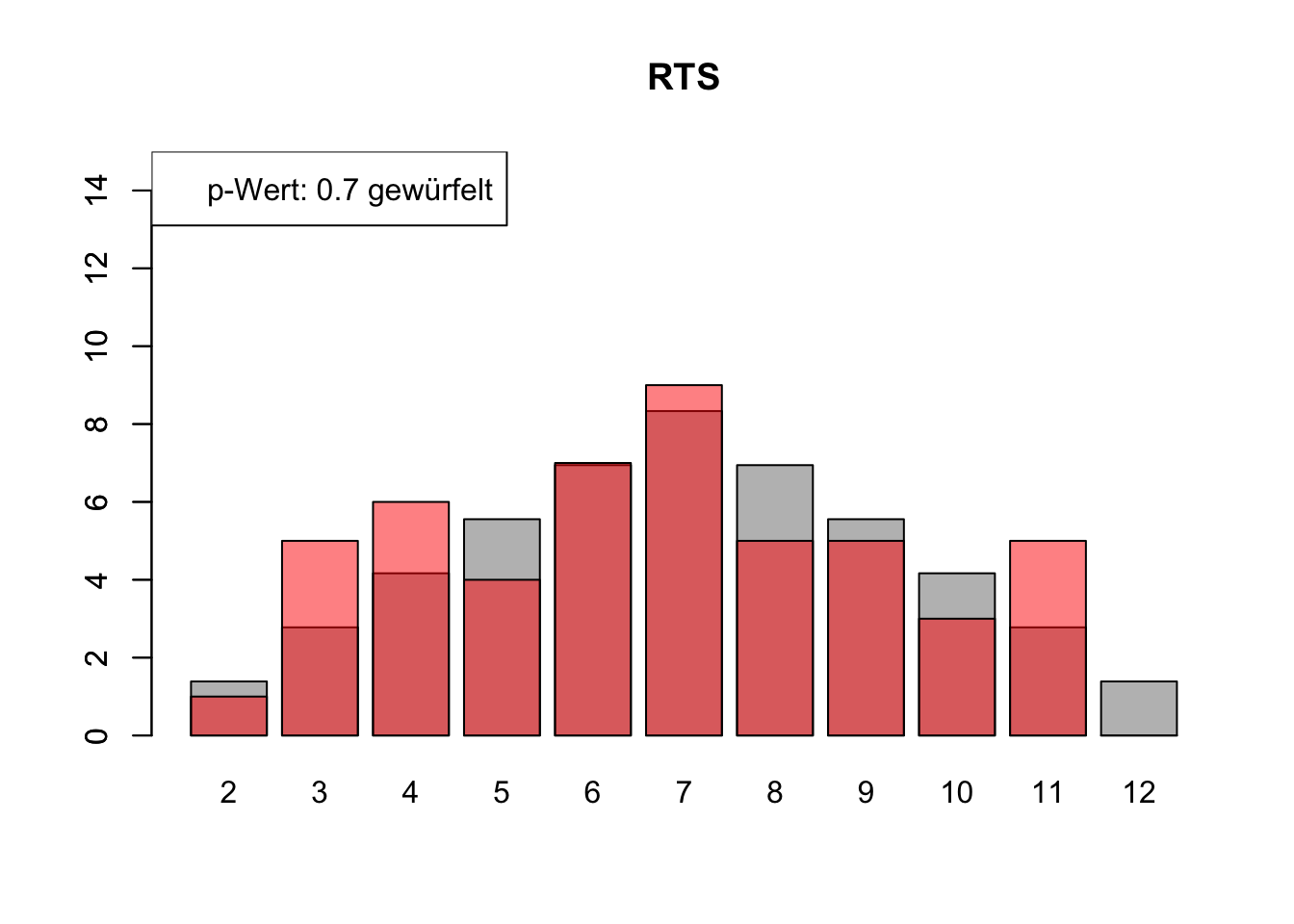
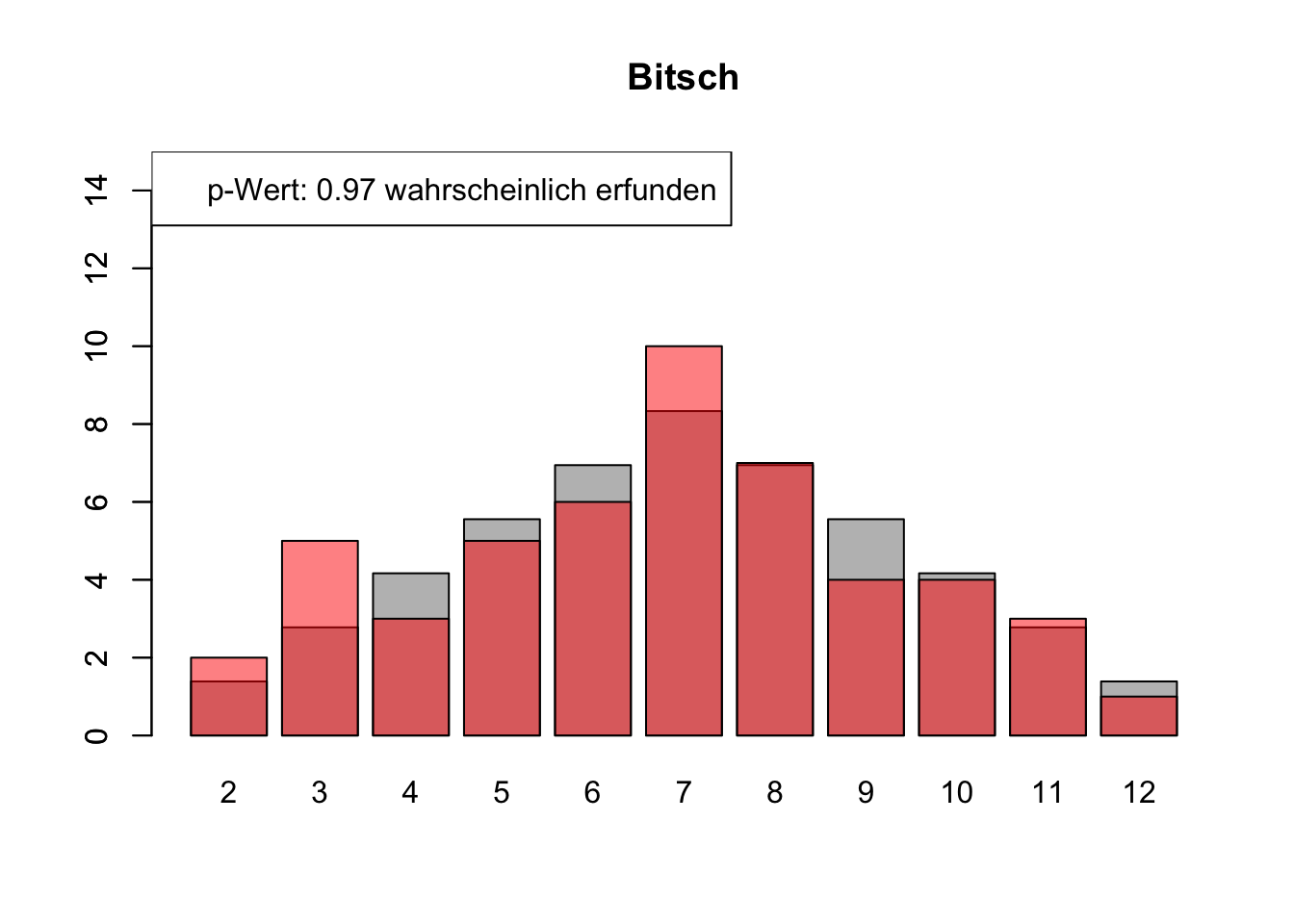
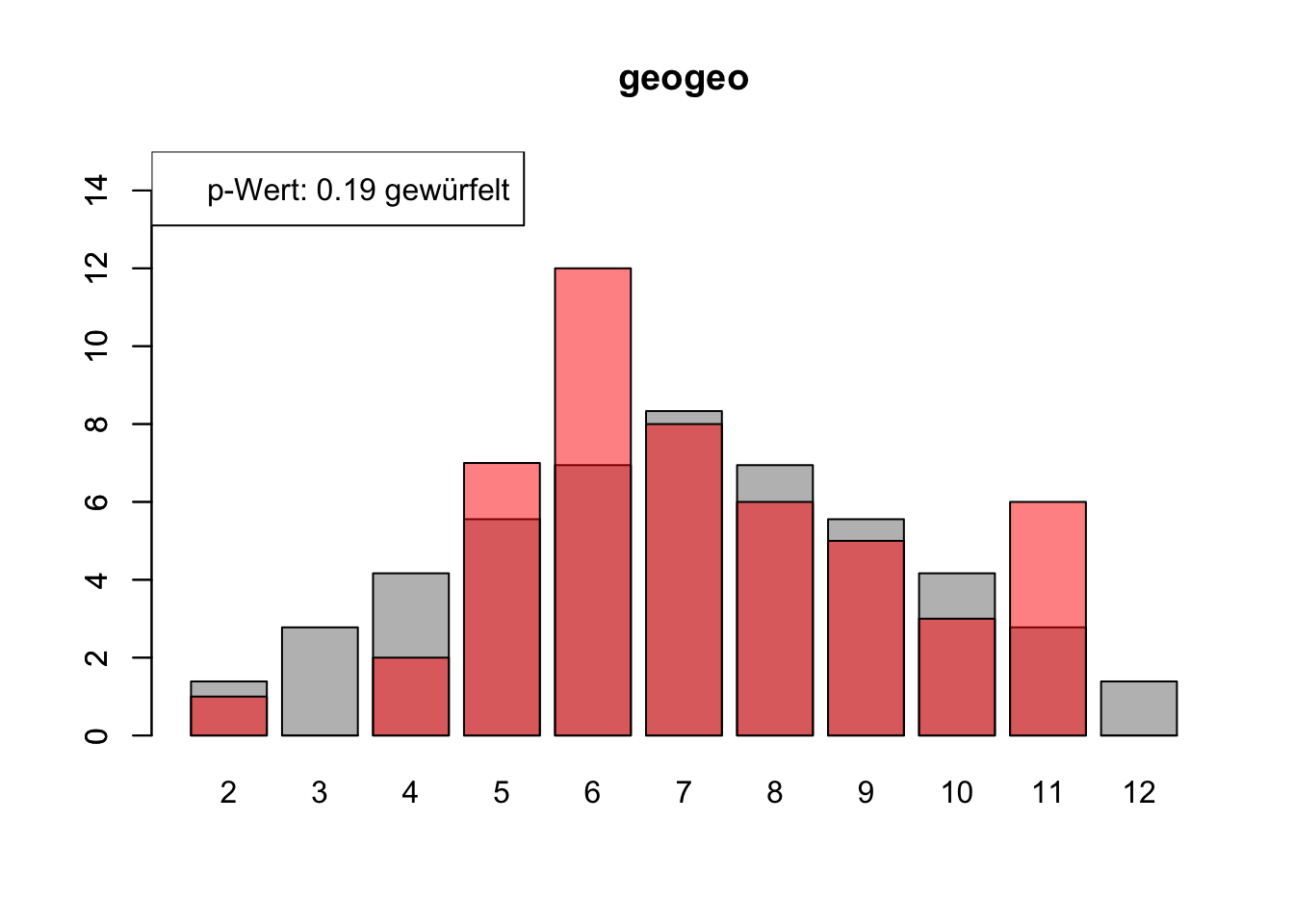
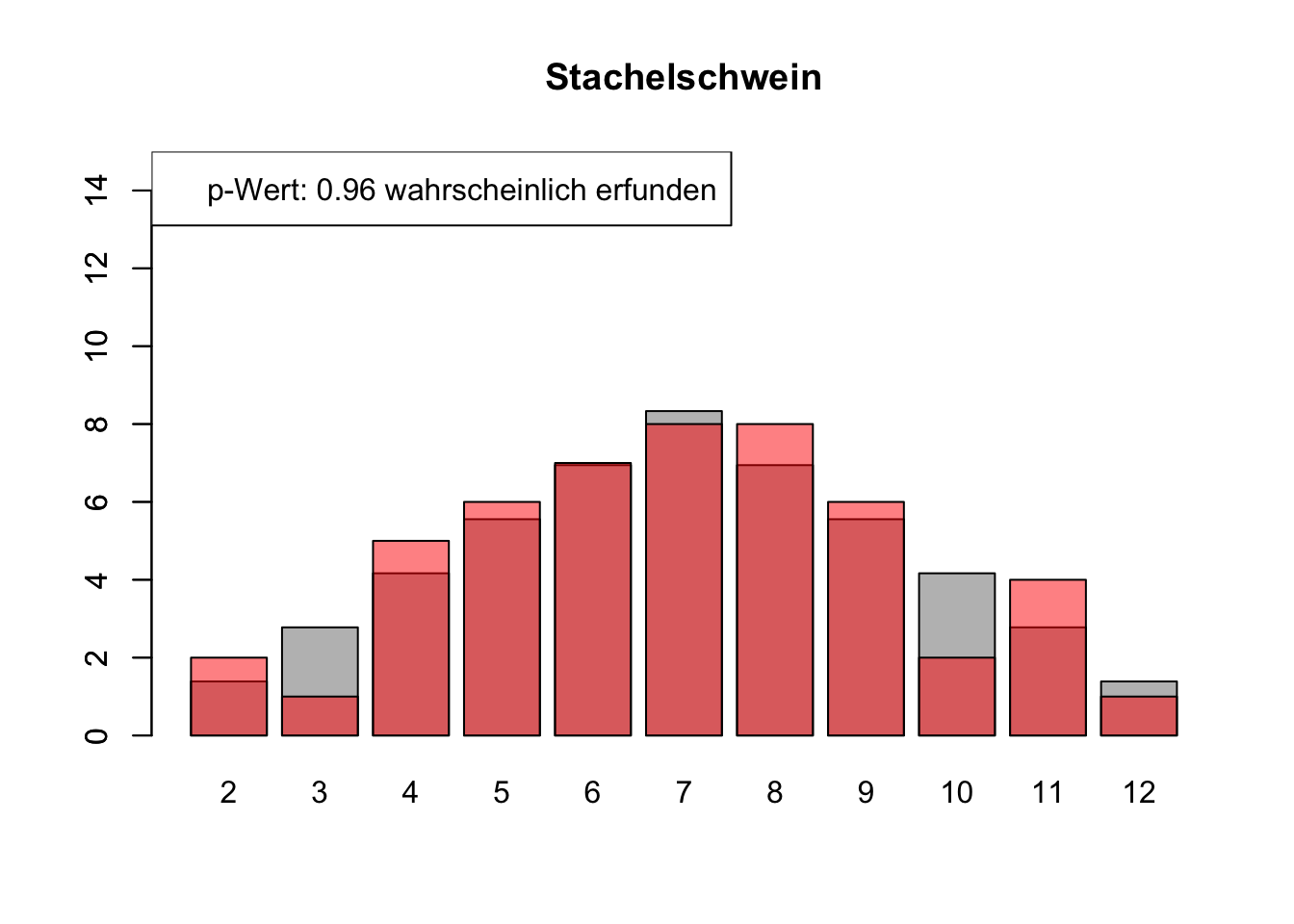
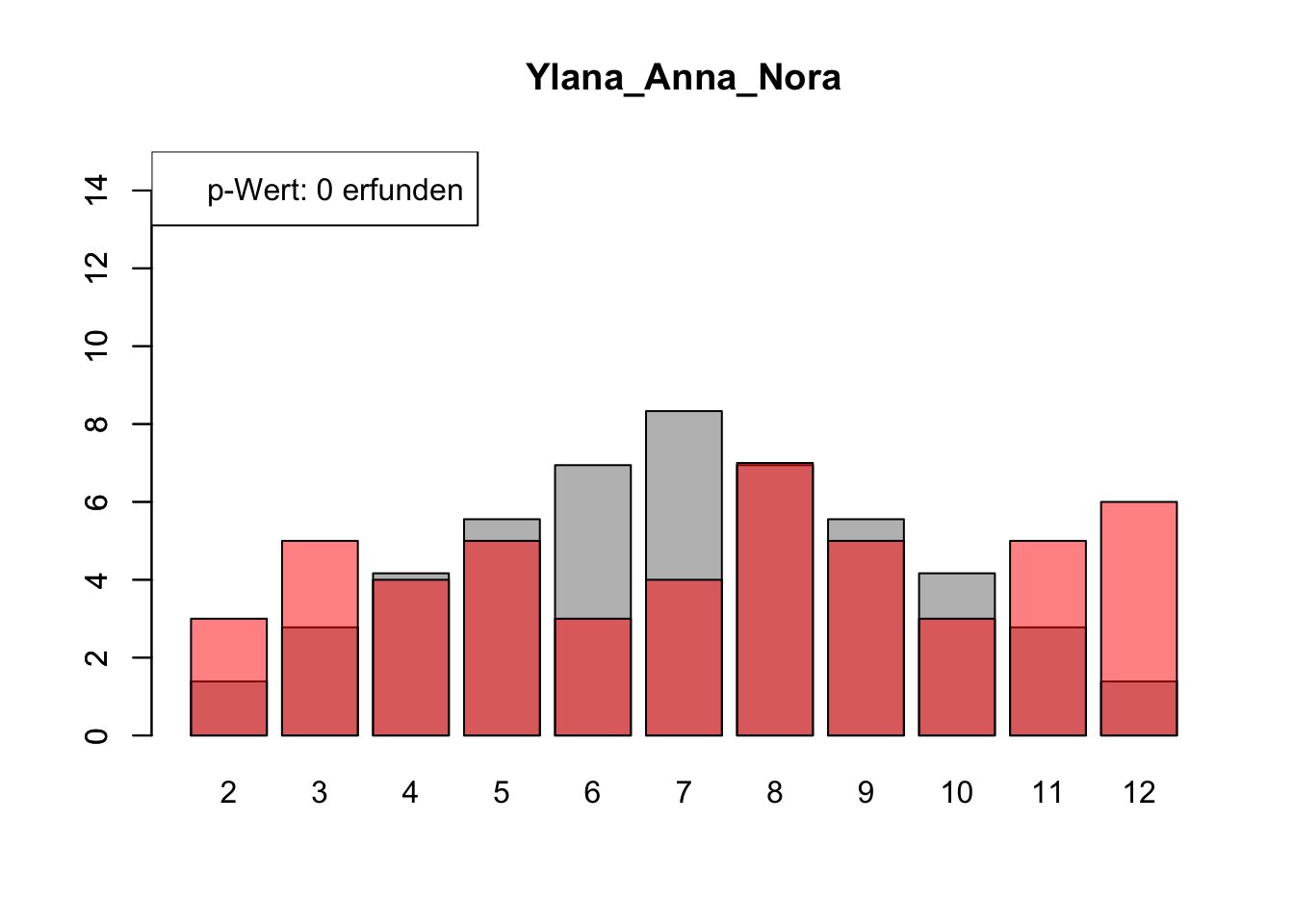
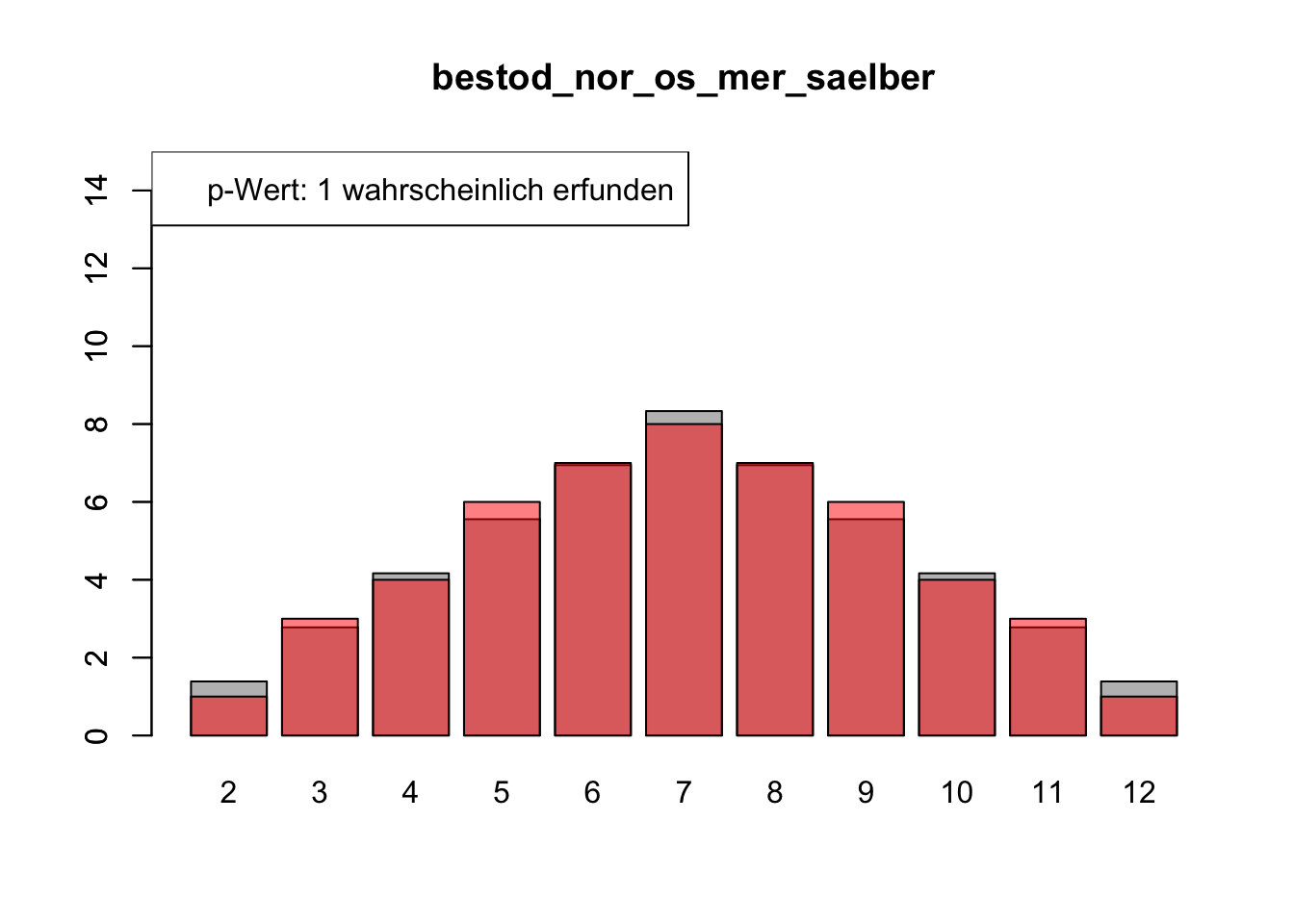
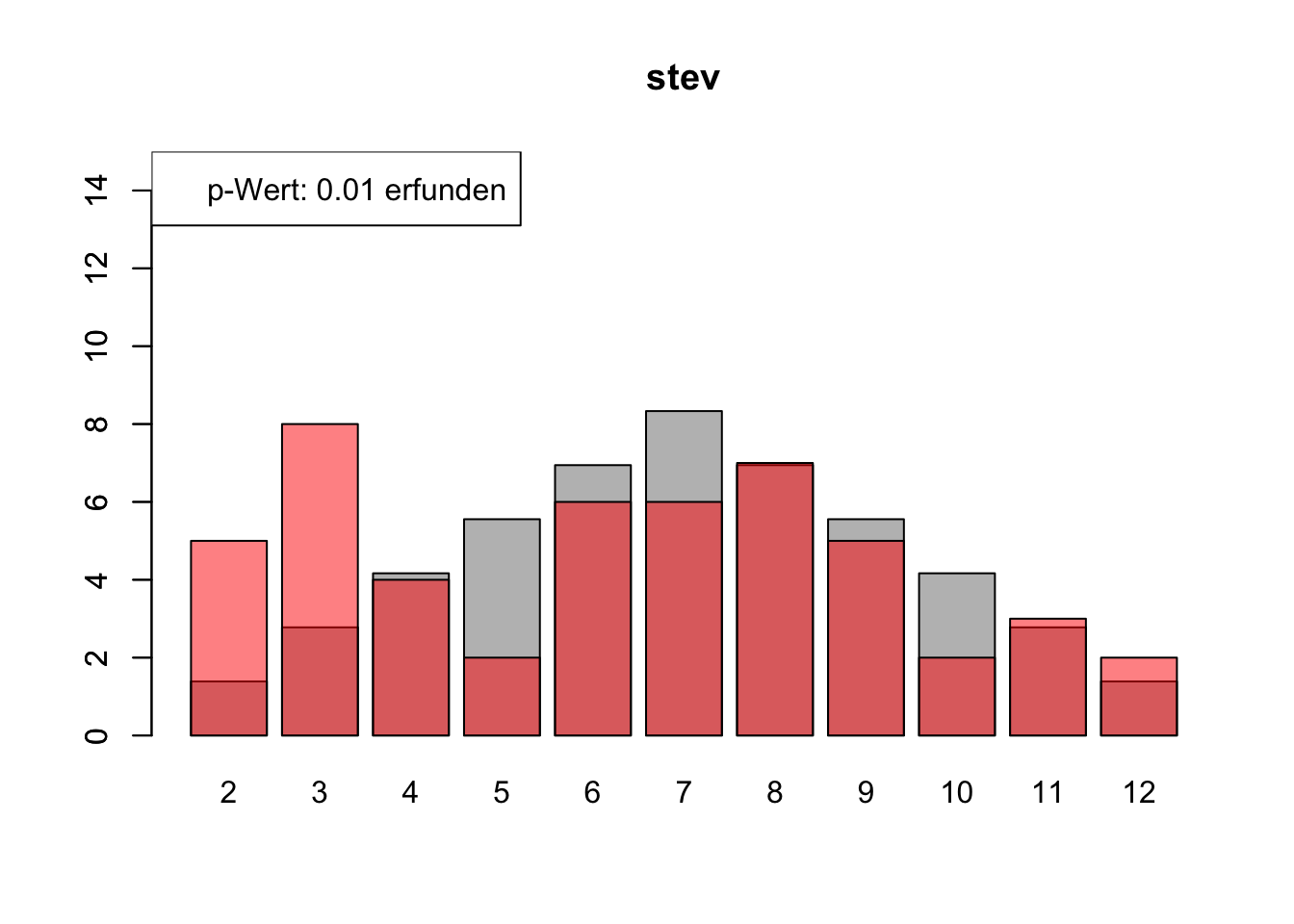
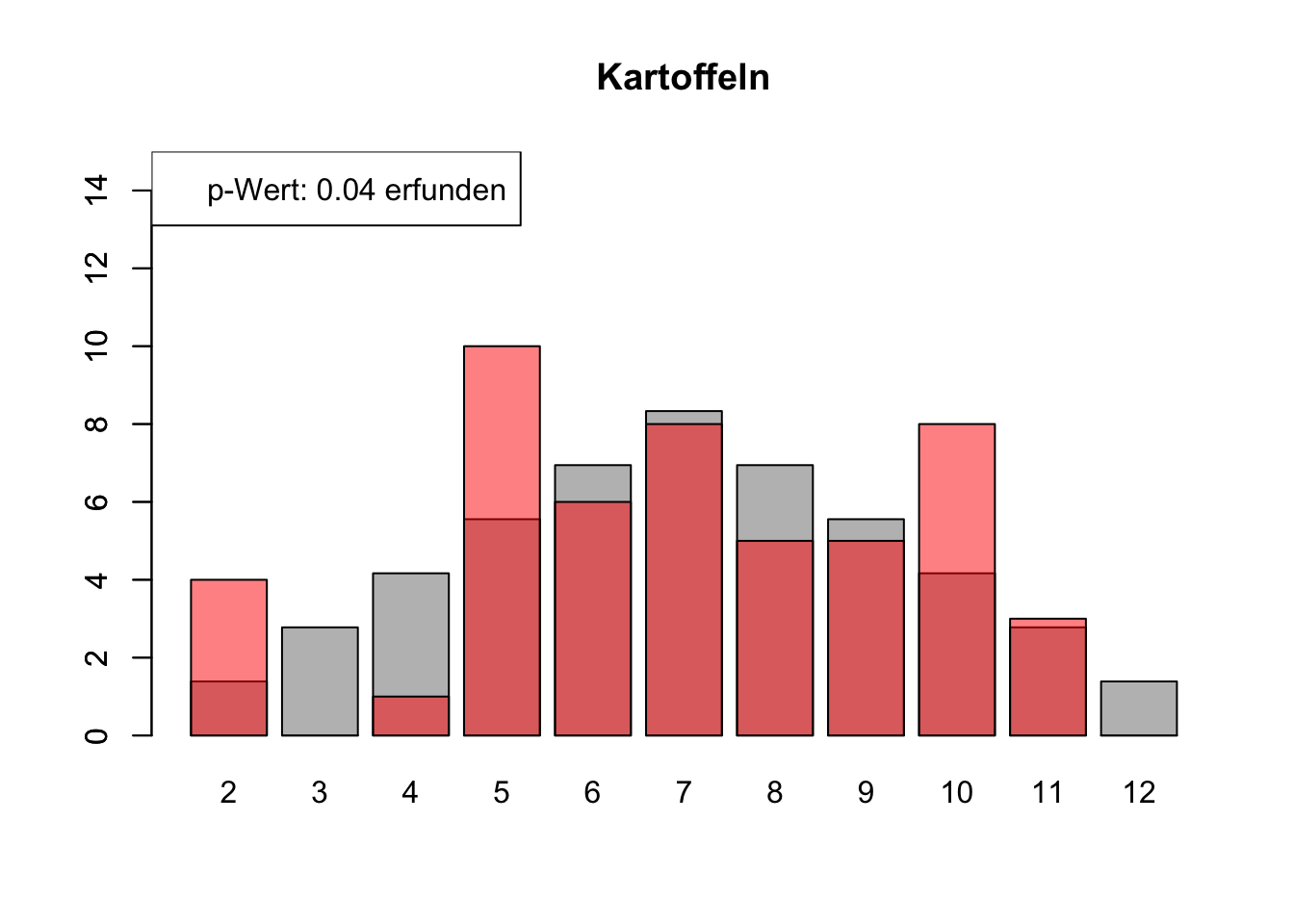
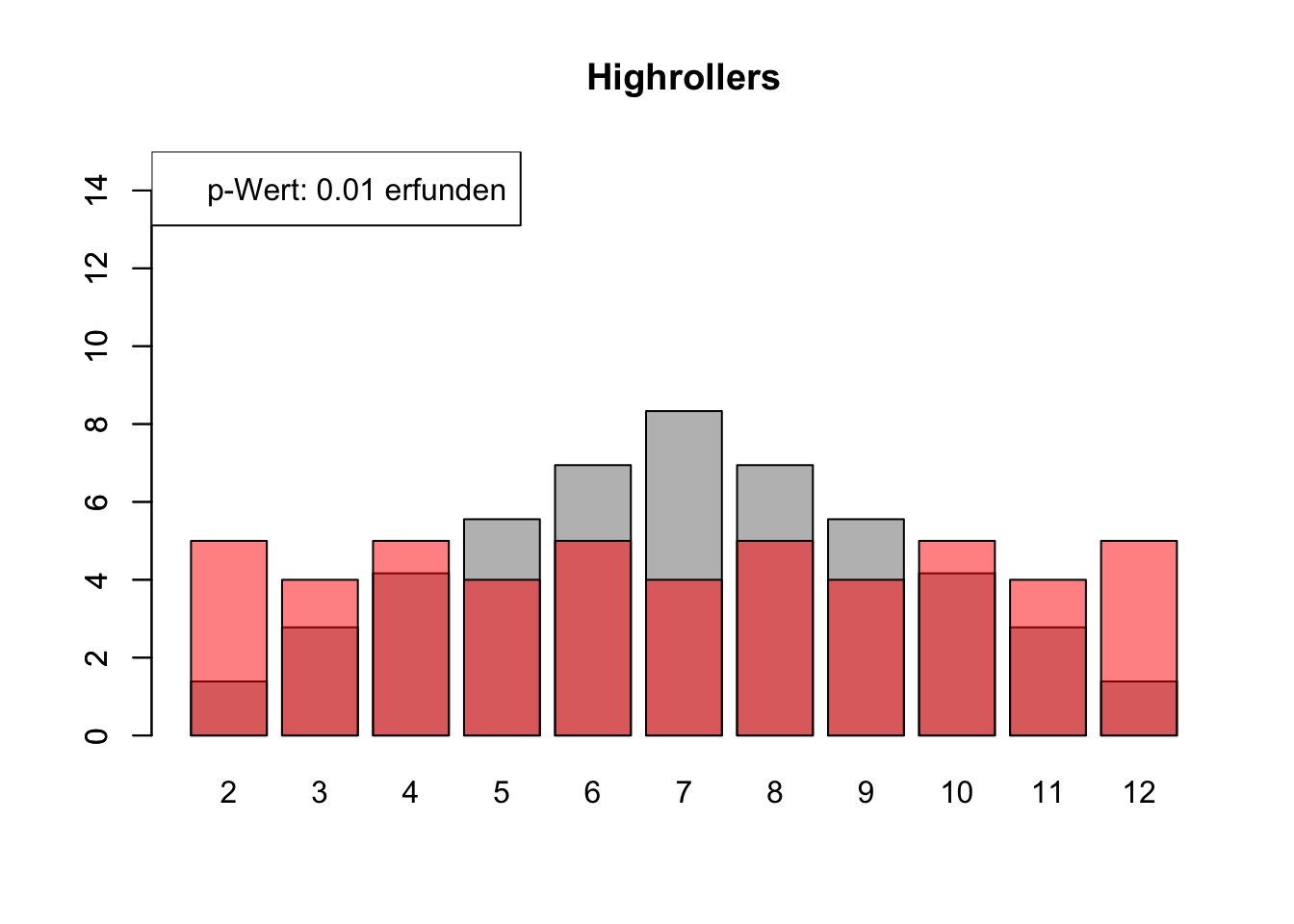
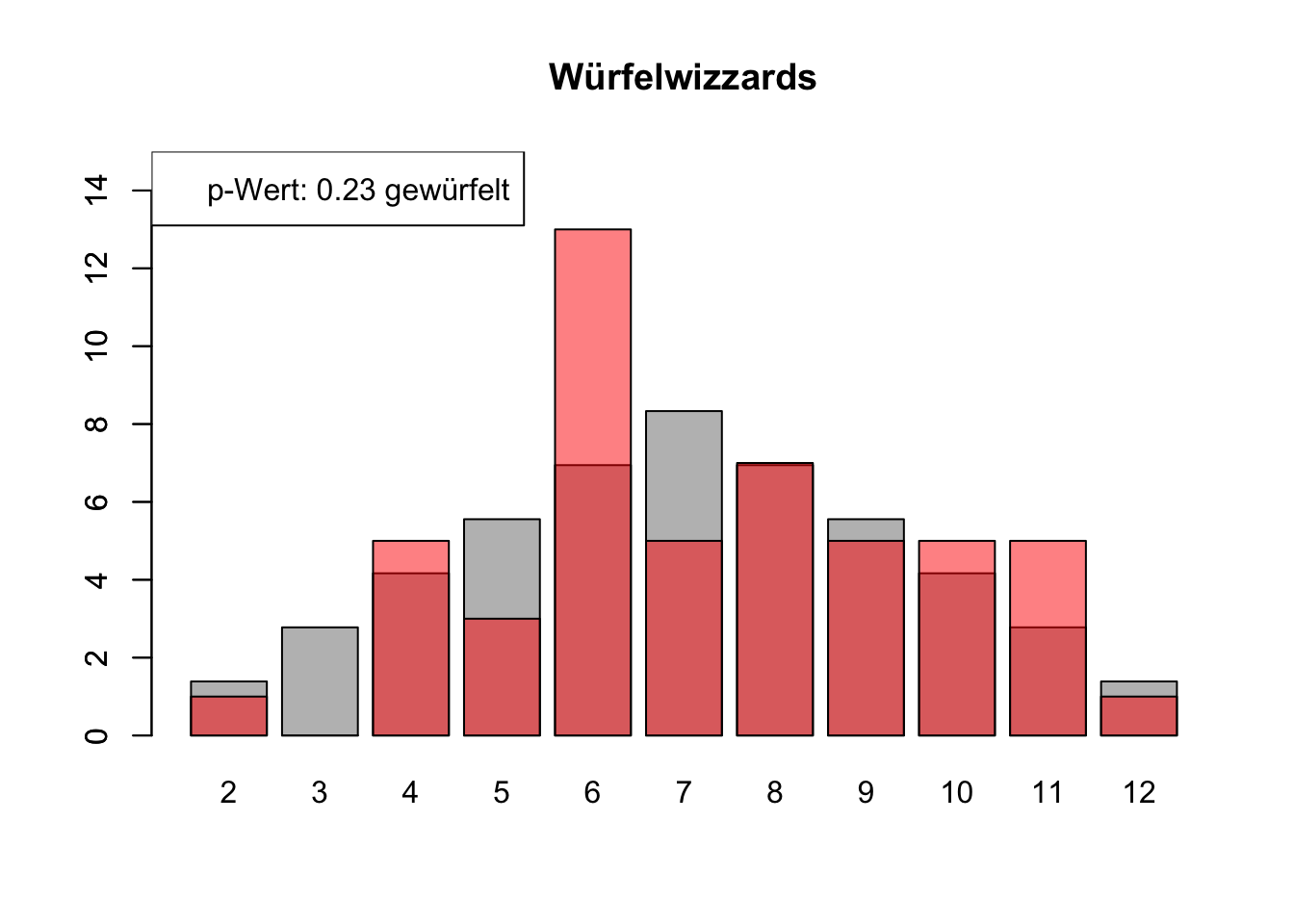
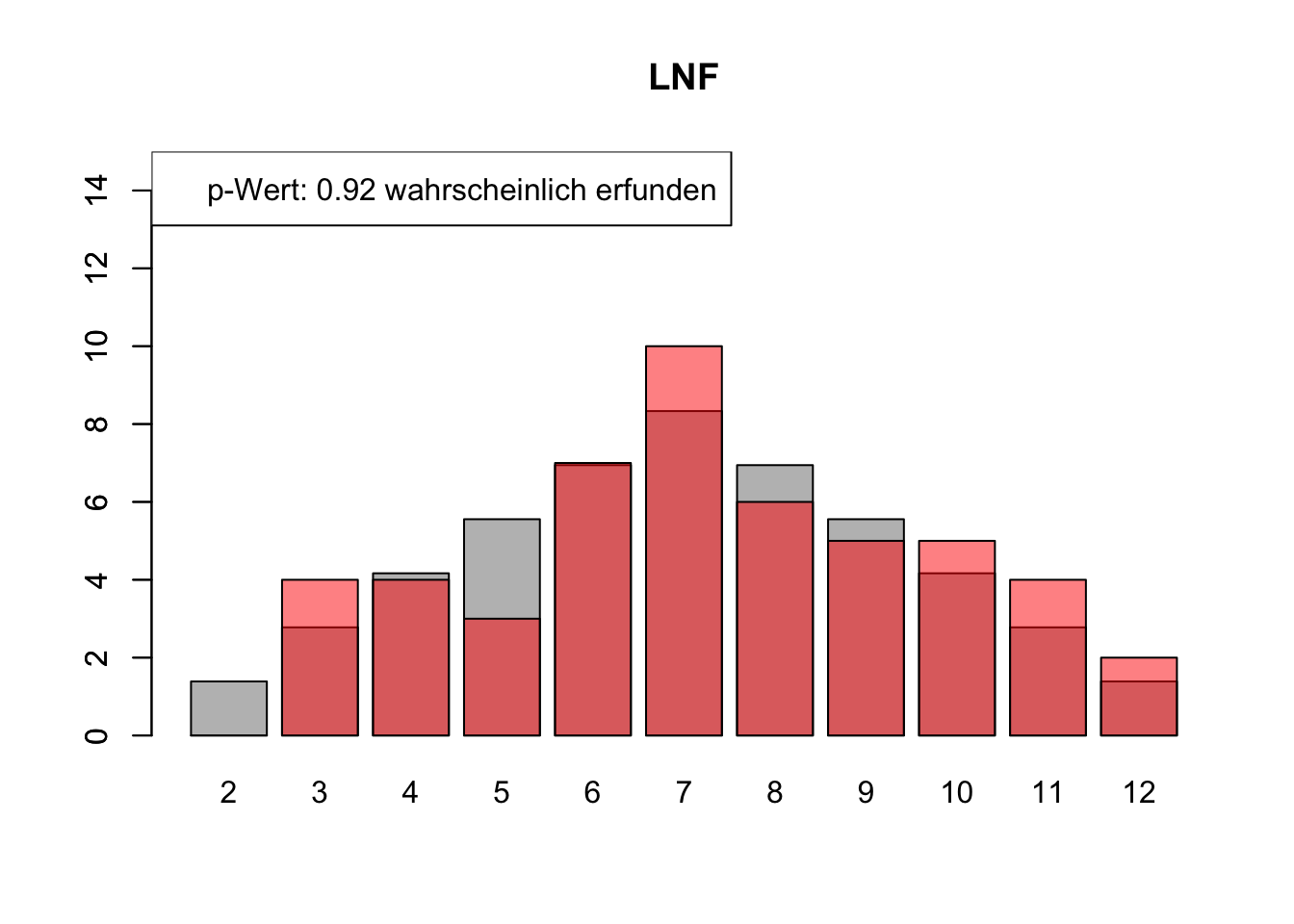
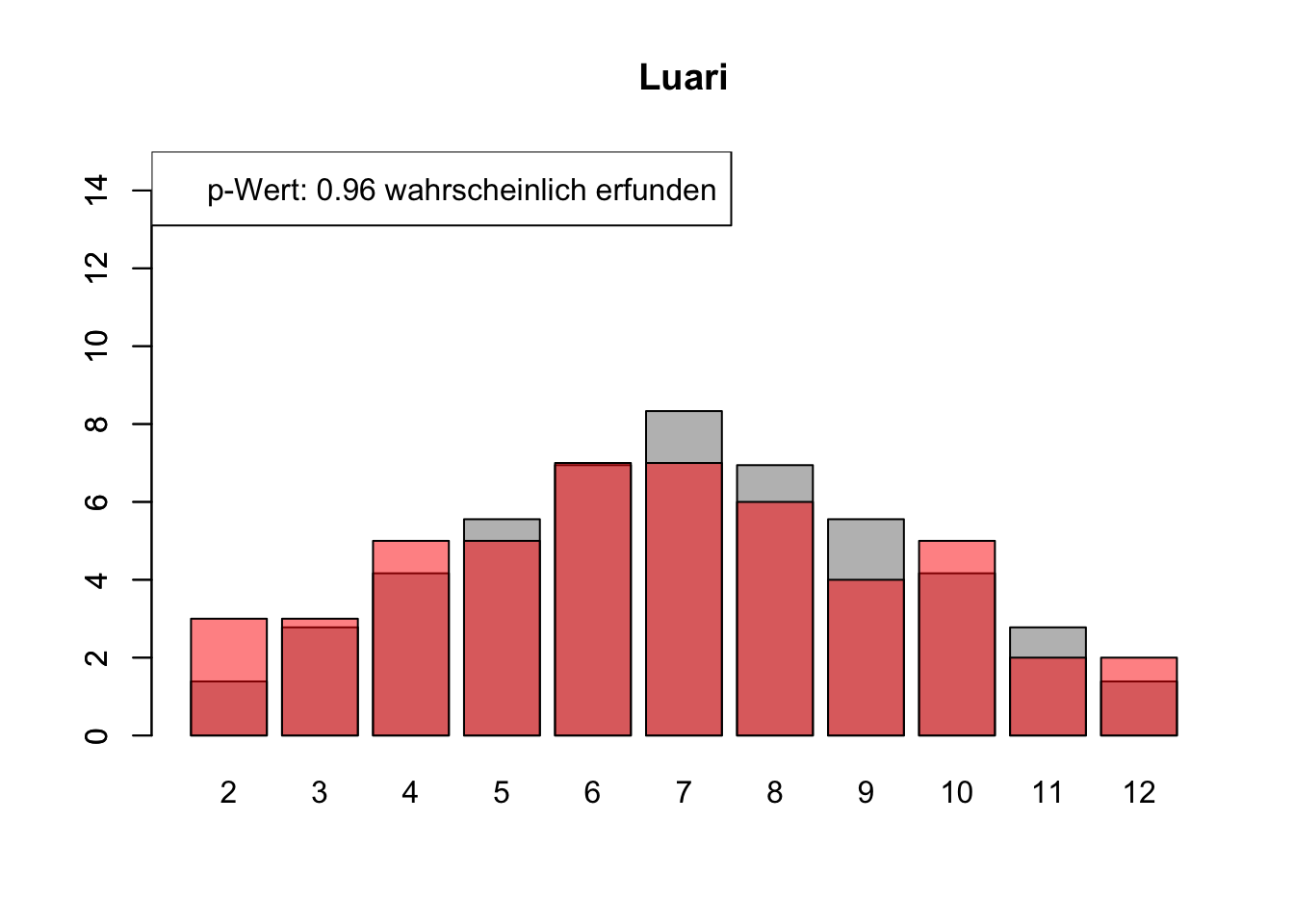
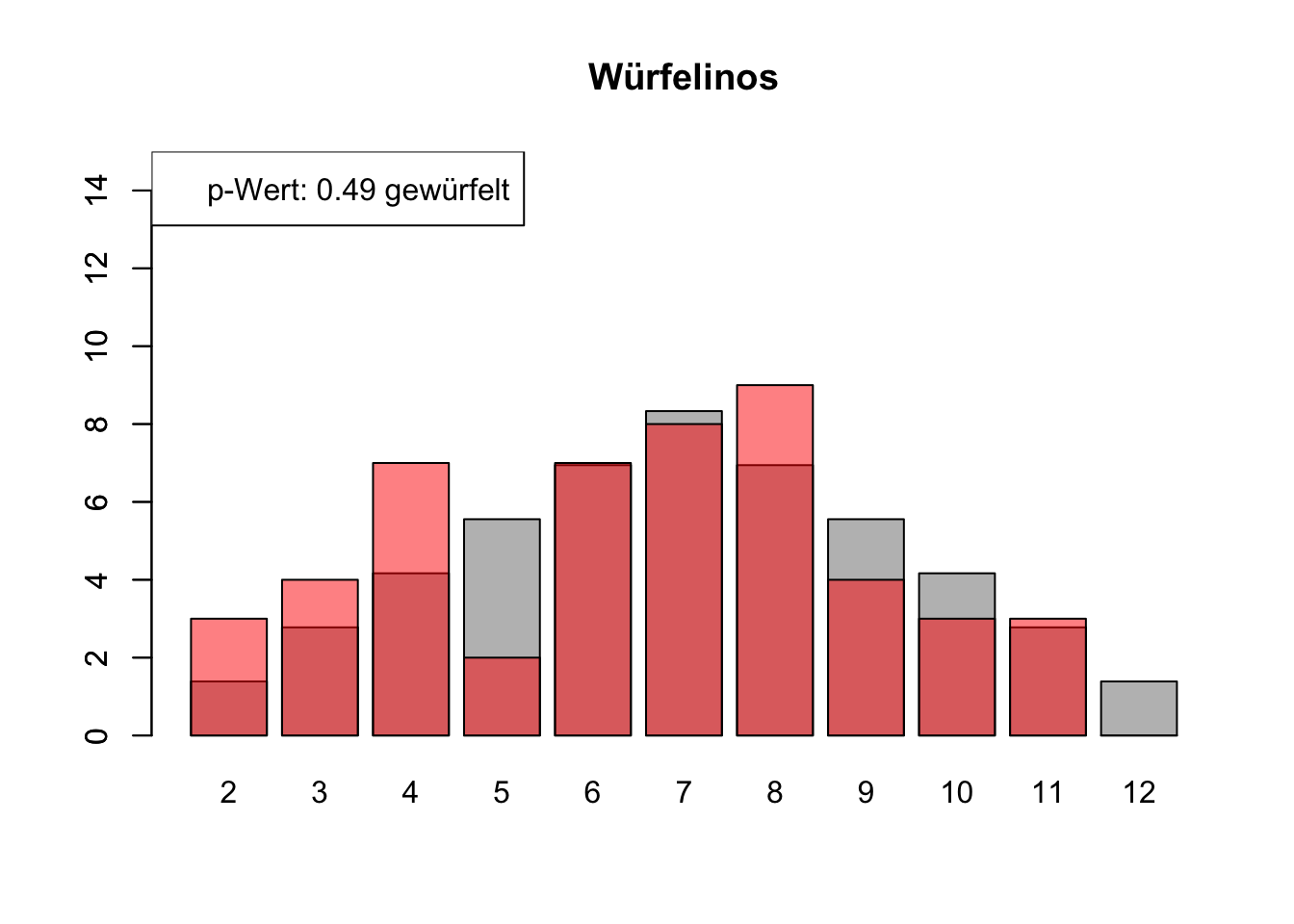
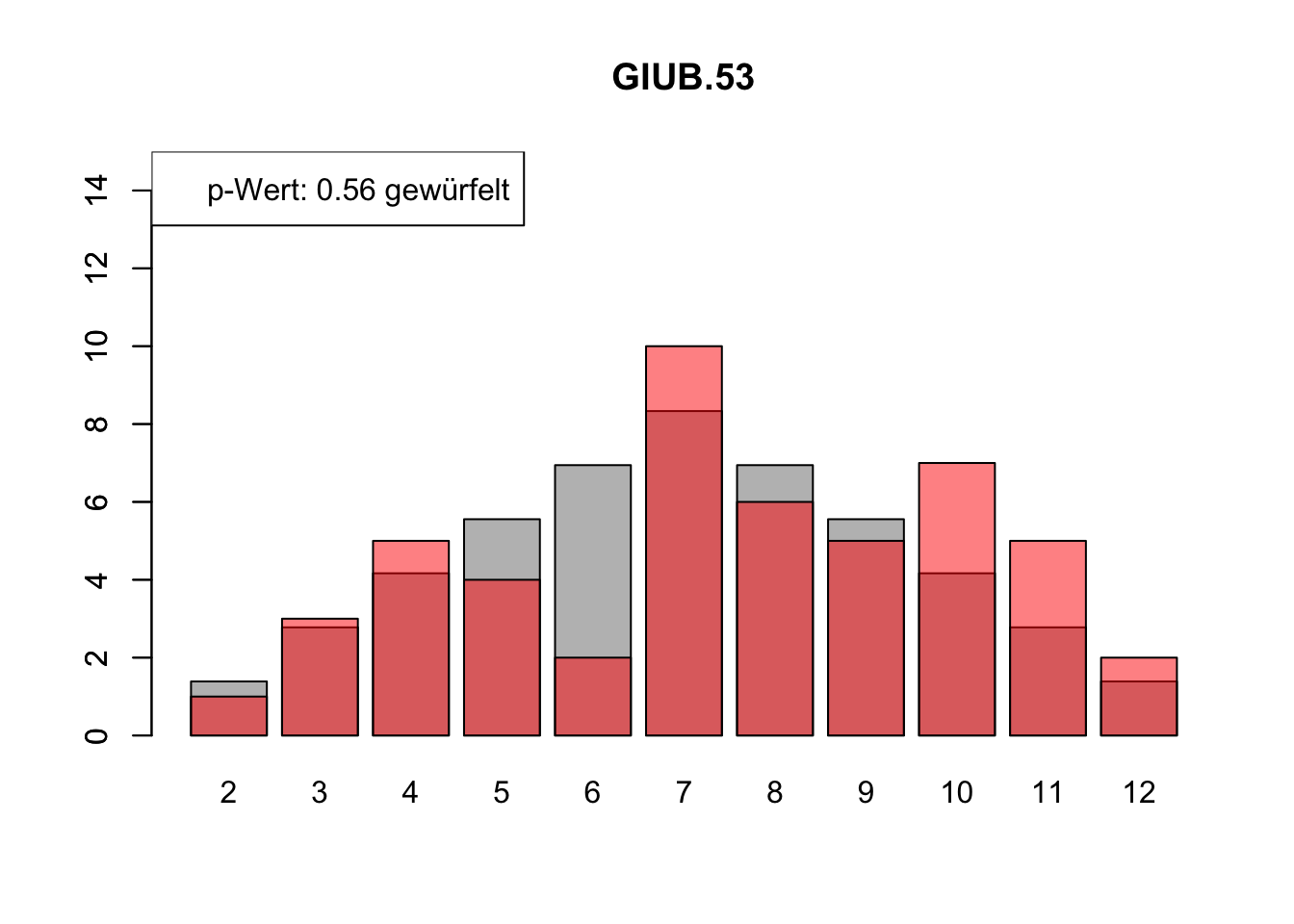
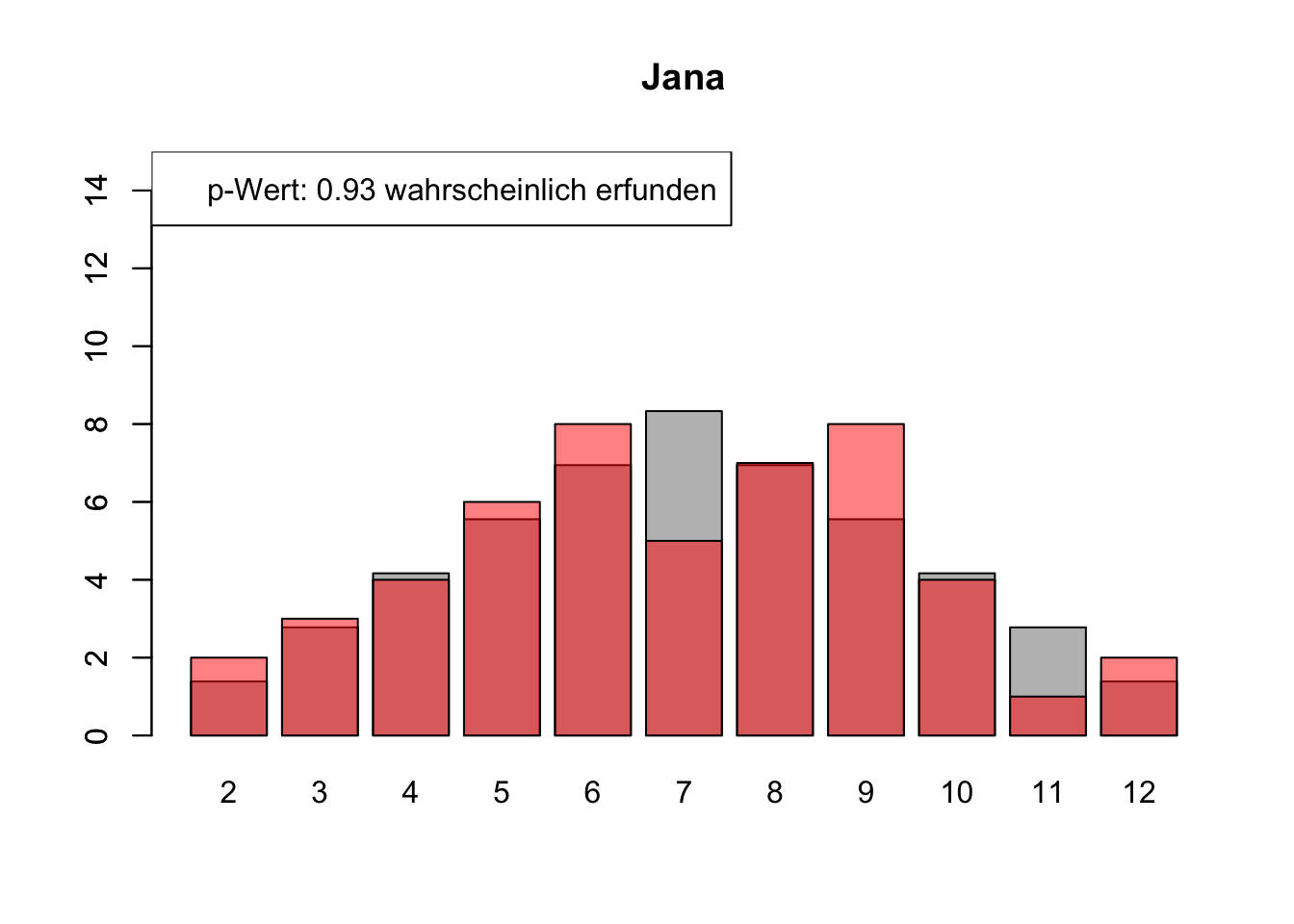
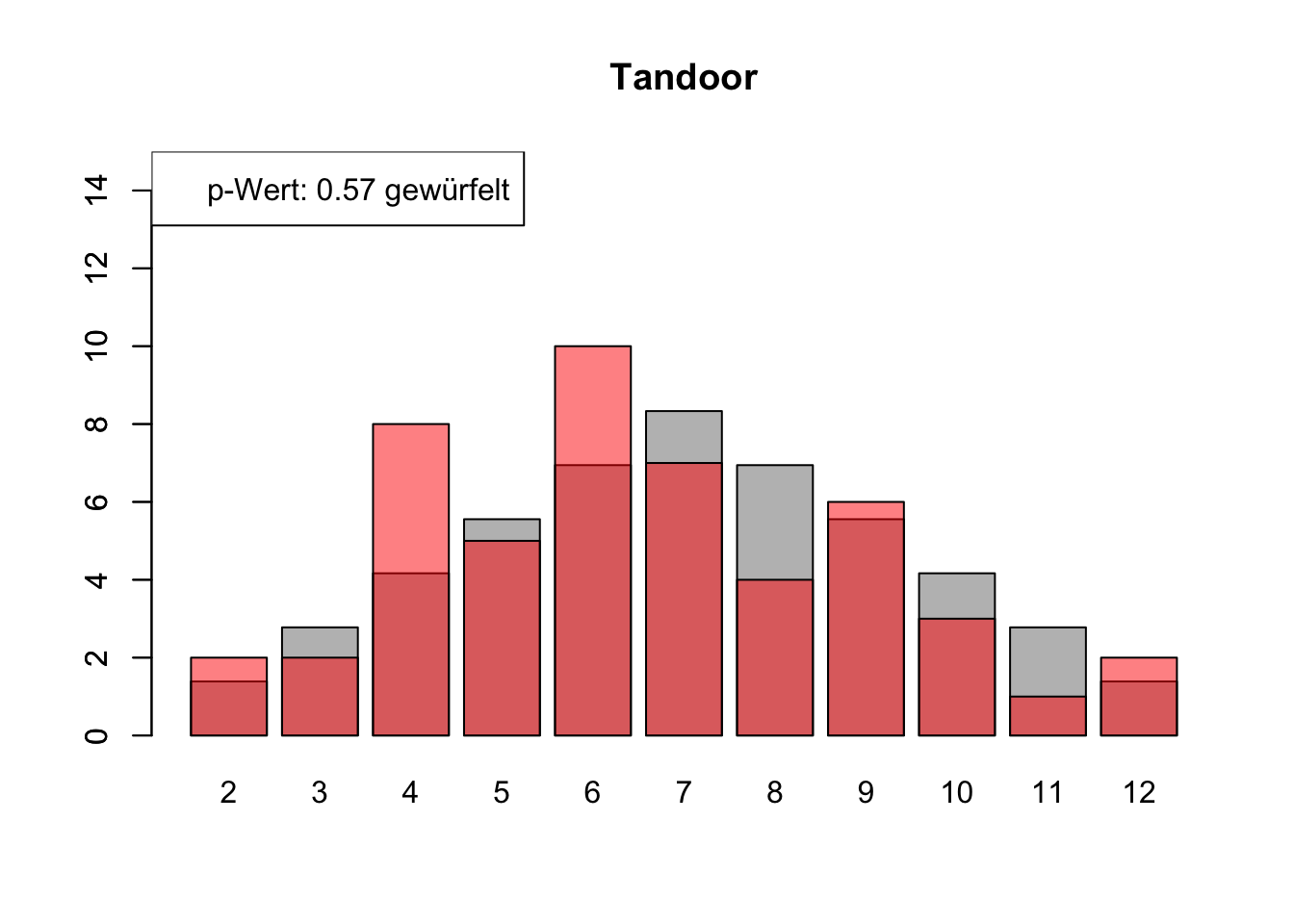
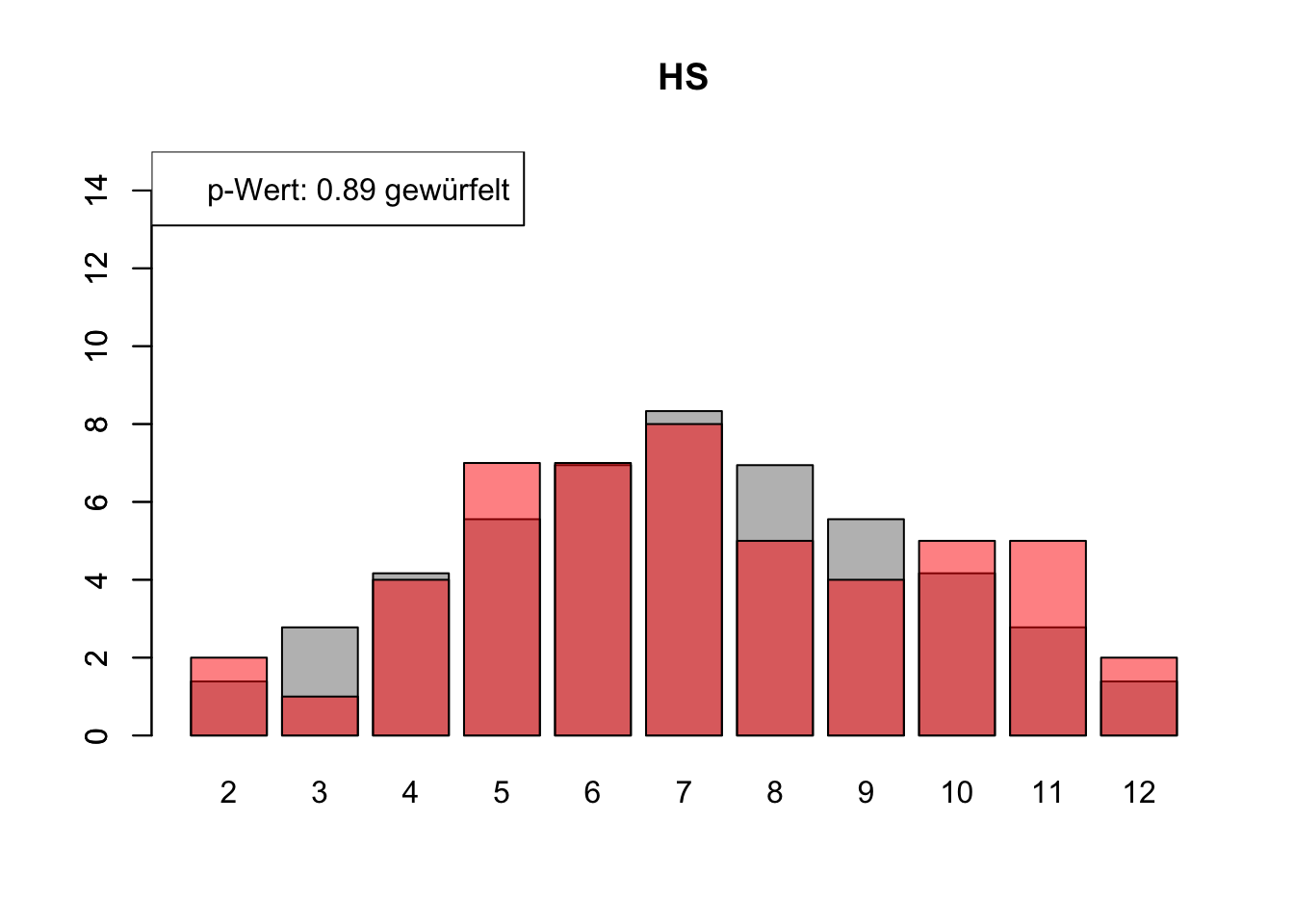
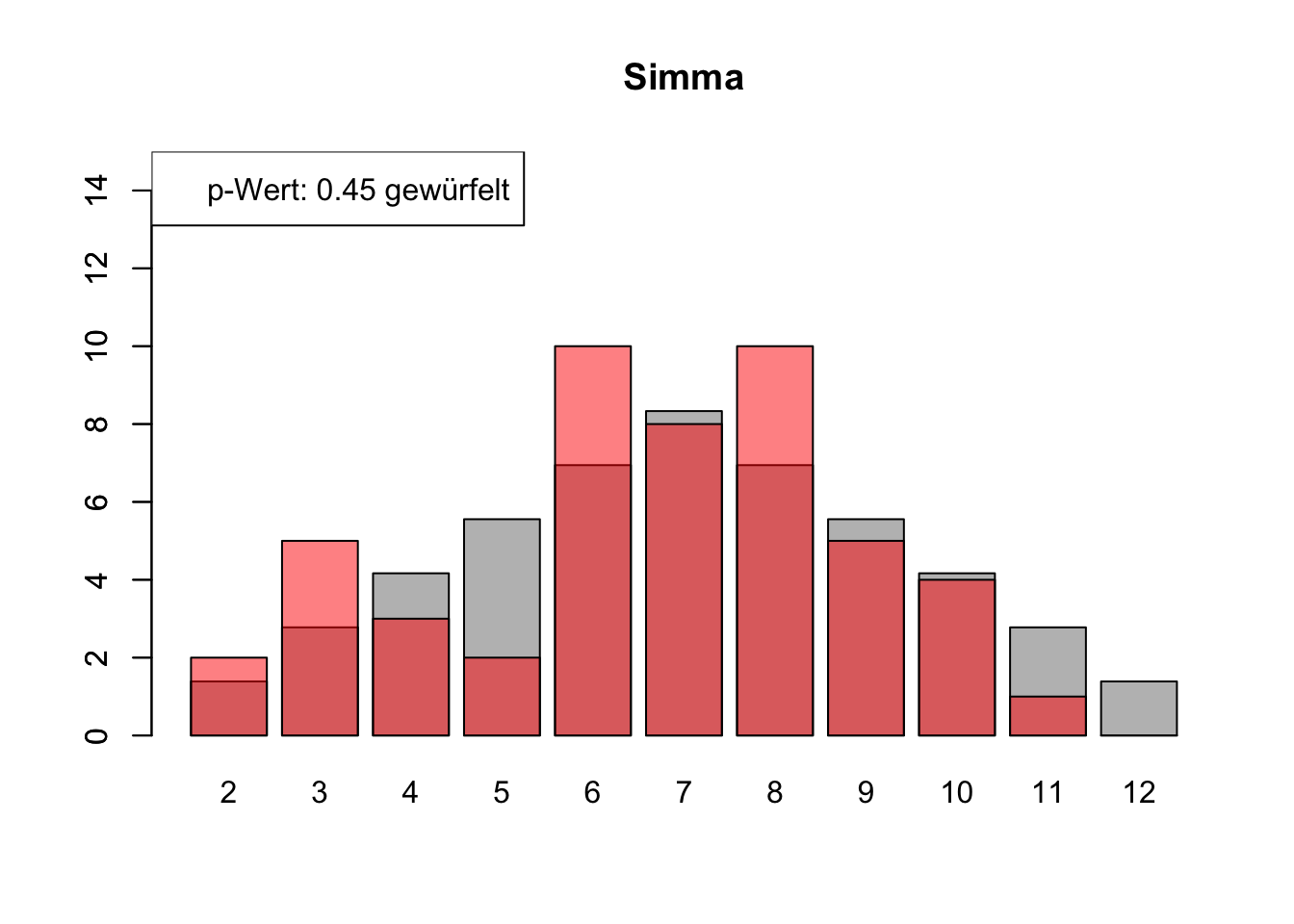
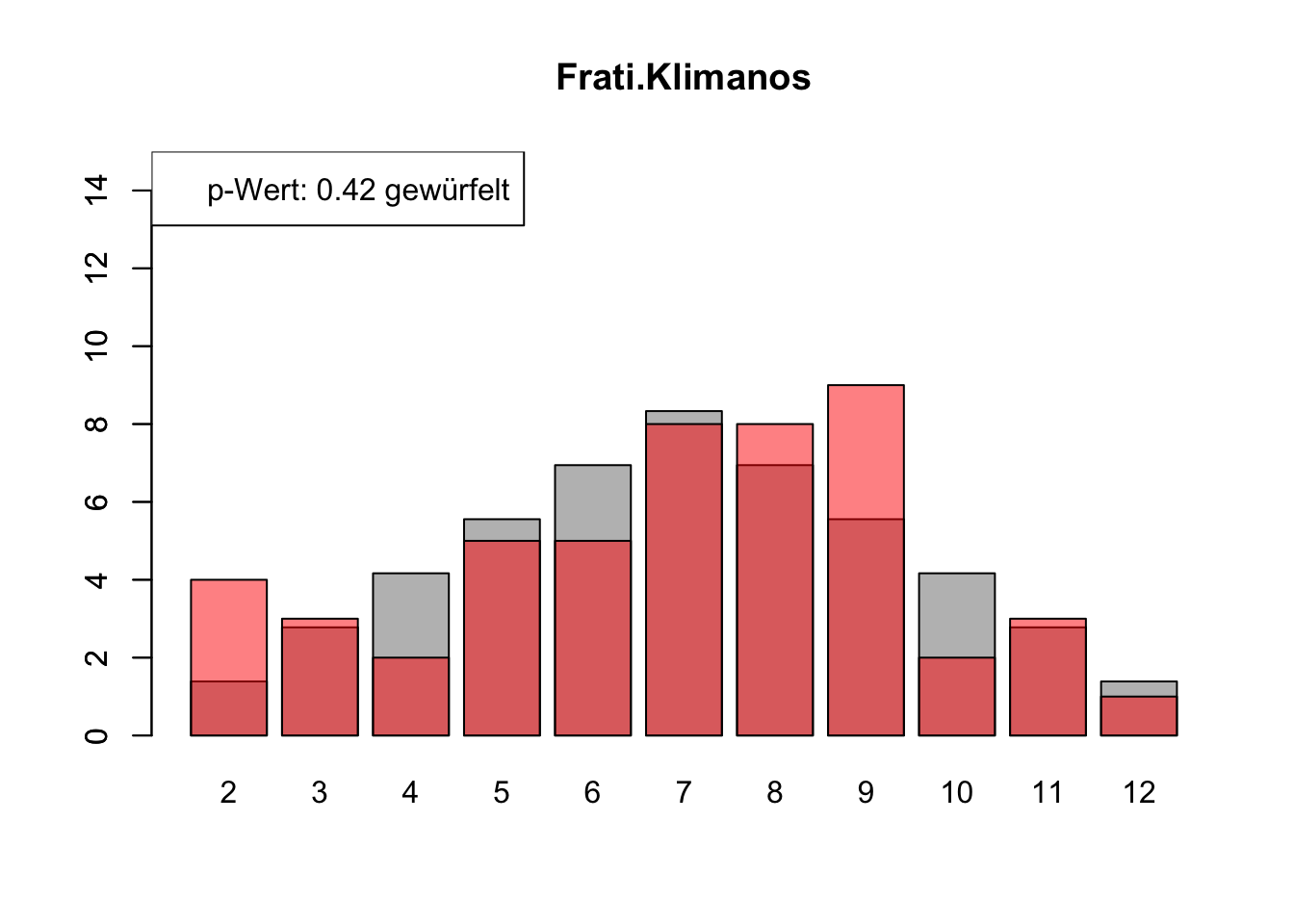
# Daten einlesenwuerfel_daten <-read.table("Data/alle_wuerfel.csv",sep =",",header =TRUE)# Initialisierung eines Vektors für p-Wertep_werte <-rep(NA, 4)# Schleife durch die relevanten Spalten (Spalten 5 bis 32)for (spalte in5:32) {# Durchführung des Chi-Quadrat-Tests chi_quadrat_test <-chisq.test(x = wuerfel_daten[, spalte],p = wuerfel_daten[, 3]) # Erwartete Wahrscheinlichkeiten in Spalte 3# p-Wert speichern p_werte <-c(p_werte, chi_quadrat_test$p.value)# Barplot für absolute Häufigkeitenbarplot( wuerfel_daten[, 4],names.arg = wuerfel_daten[, 1],col ="grey",ylim =c(0, 15),main =colnames(wuerfel_daten)[spalte] )# Neuen Plot für die Vergleichsdaten auf derselben Grafikpar(new =TRUE)barplot( wuerfel_daten[, spalte],col =rgb(1, 0, 0, 0.5, maxColorValue =1),ylim =c(0, 15) )# Legende hinzufügen, die den p-Wert anzeigtlegend("topleft",paste("p-Wert:", round(chi_quadrat_test$p.value, 2),ifelse(chi_quadrat_test$p.value <0.05, "erfunden",ifelse( chi_quadrat_test$p.value >0.9,"wahrscheinlich erfunden","gewürfelt") ) ) )# Anhalten für visuelle Überprüfung# cat("Drücke Enter, um fortzufahren...")# readline()}
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
Warning in chisq.test(x = wuerfel_daten[, spalte], p = wuerfel_daten[, 3]):
Chi-squared approximation may be incorrect
# Ergebniszeilen für die Interpretation der p-Werte hinzufügeninterpretation <-ifelse( p_werte <0.05| p_werte >0.9,"erfunden", "gewürfelt")# p-Werte und die neue Interpretation an den DataFrame anhängenwuerfel_daten <-rbind( wuerfel_daten, p_werte, interpretation)# Überarbeiteter DataFrame mit neuen Zeilen für p-Werte und ihre Interpretation
E.3 Psychologie Experiment
Daten einlesen
psychologieExperiment <-read.table('Data/Psycho_Exp_Ergebnisse2_2024-10-28.csv',sep =',',header =TRUE,na.strings ='999')# Spalten im DataFrame umbenennencolnames(psychologieExperiment) <-c("Gefuehl_Vor_SelberGutesTun","Gefuehl_Nach_SelberGutesTun","Gefuehl_Vor_AnderenGutesTun","Gefuehl_Nach_AnderenGutesTun")
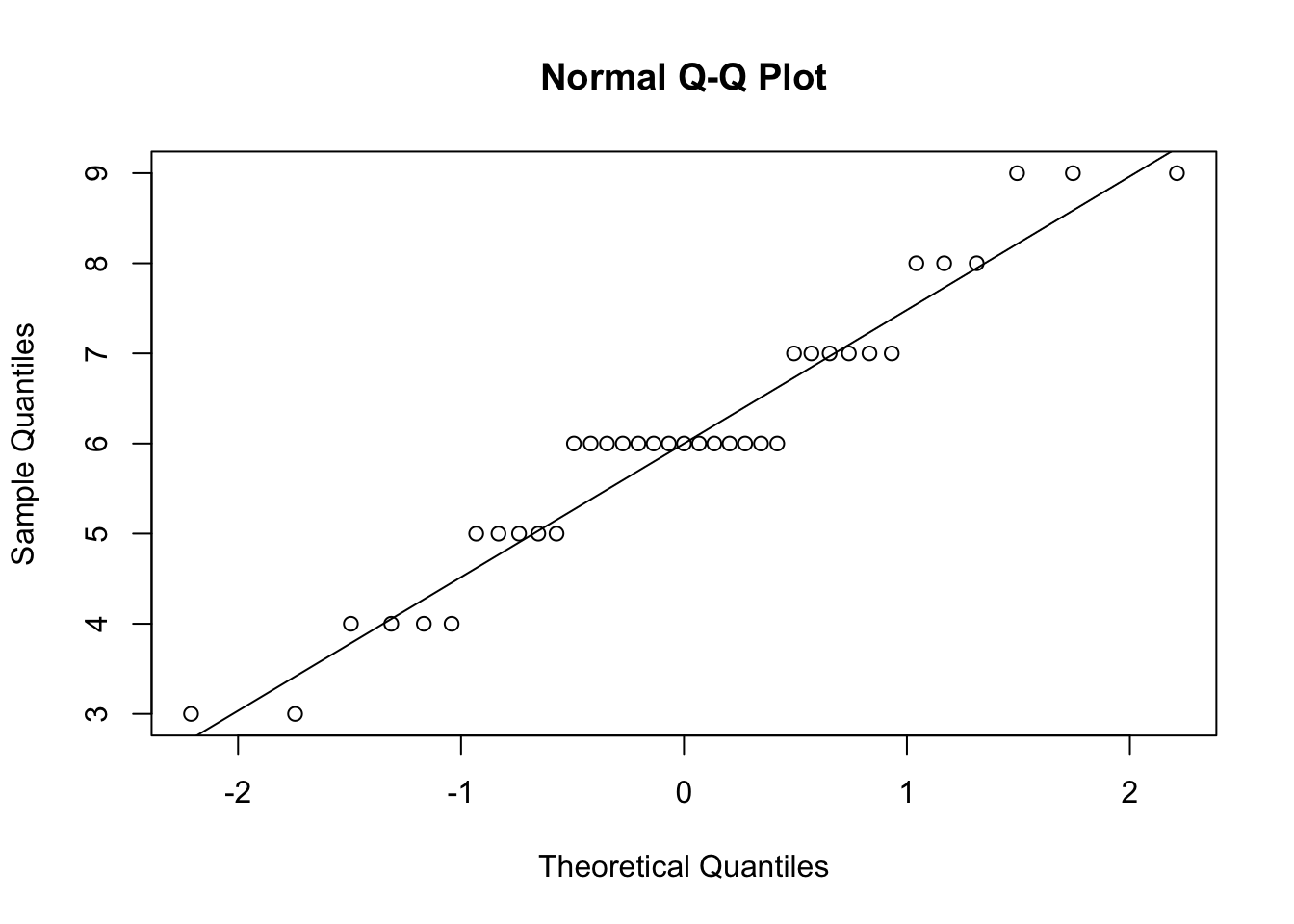
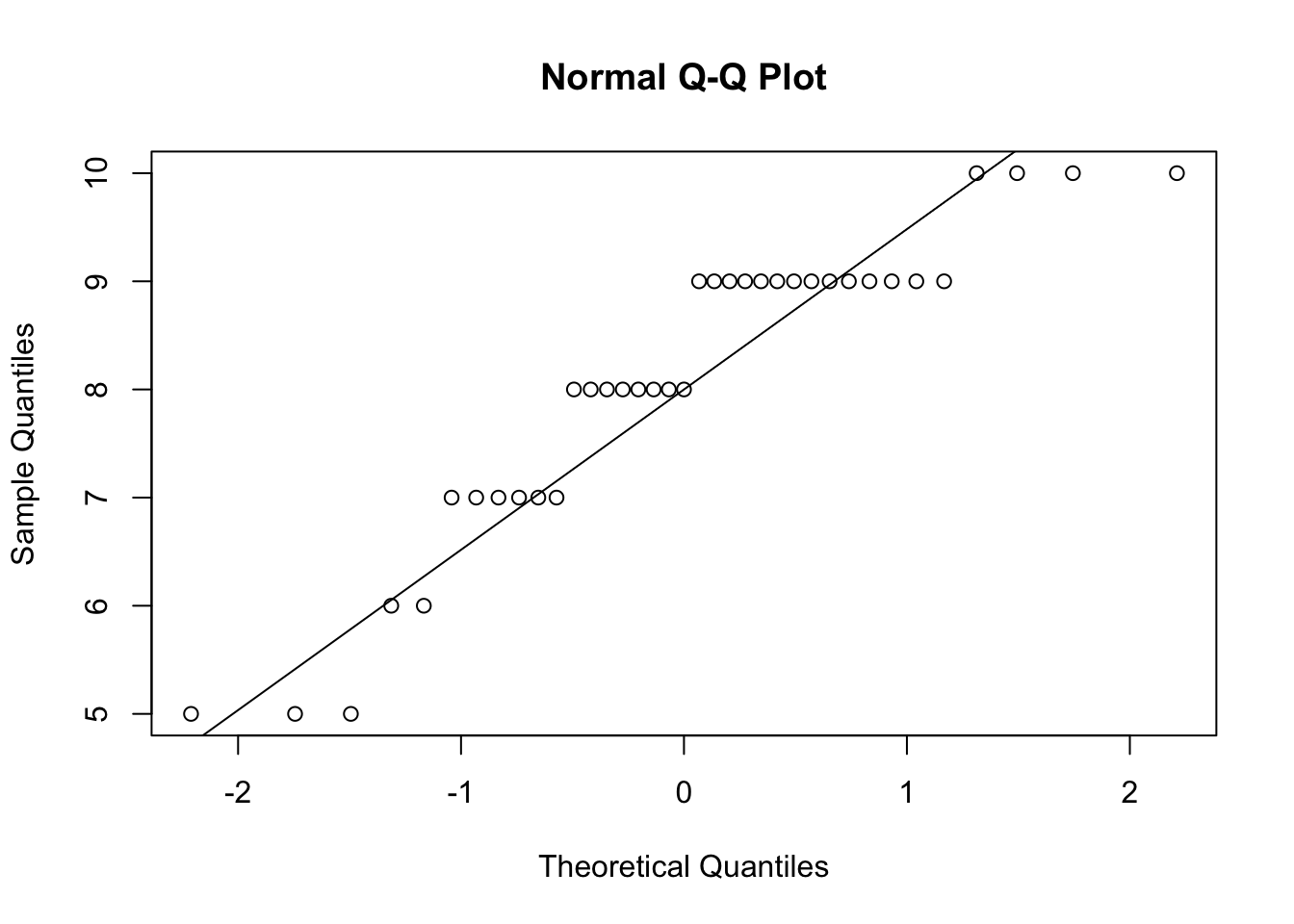
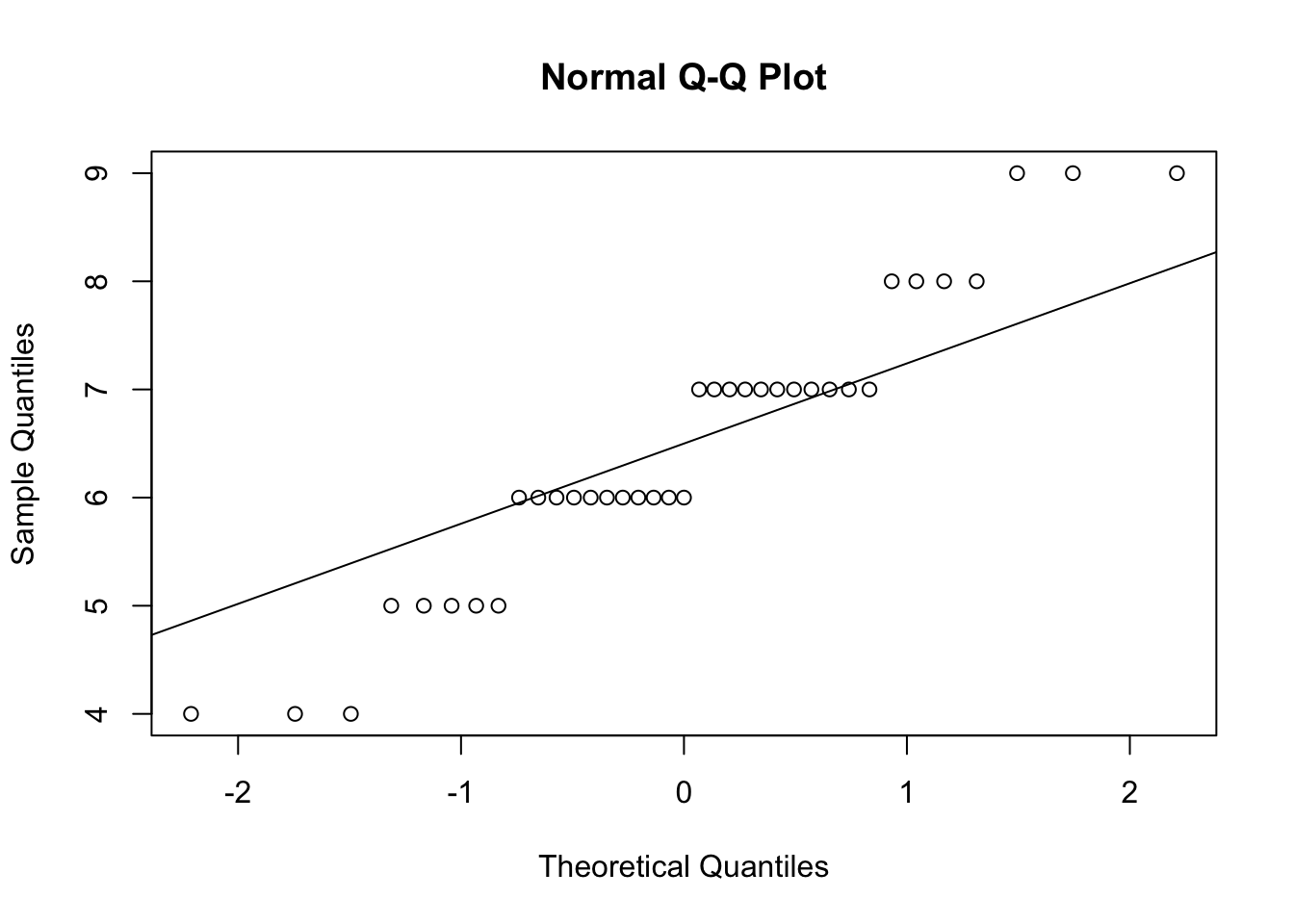
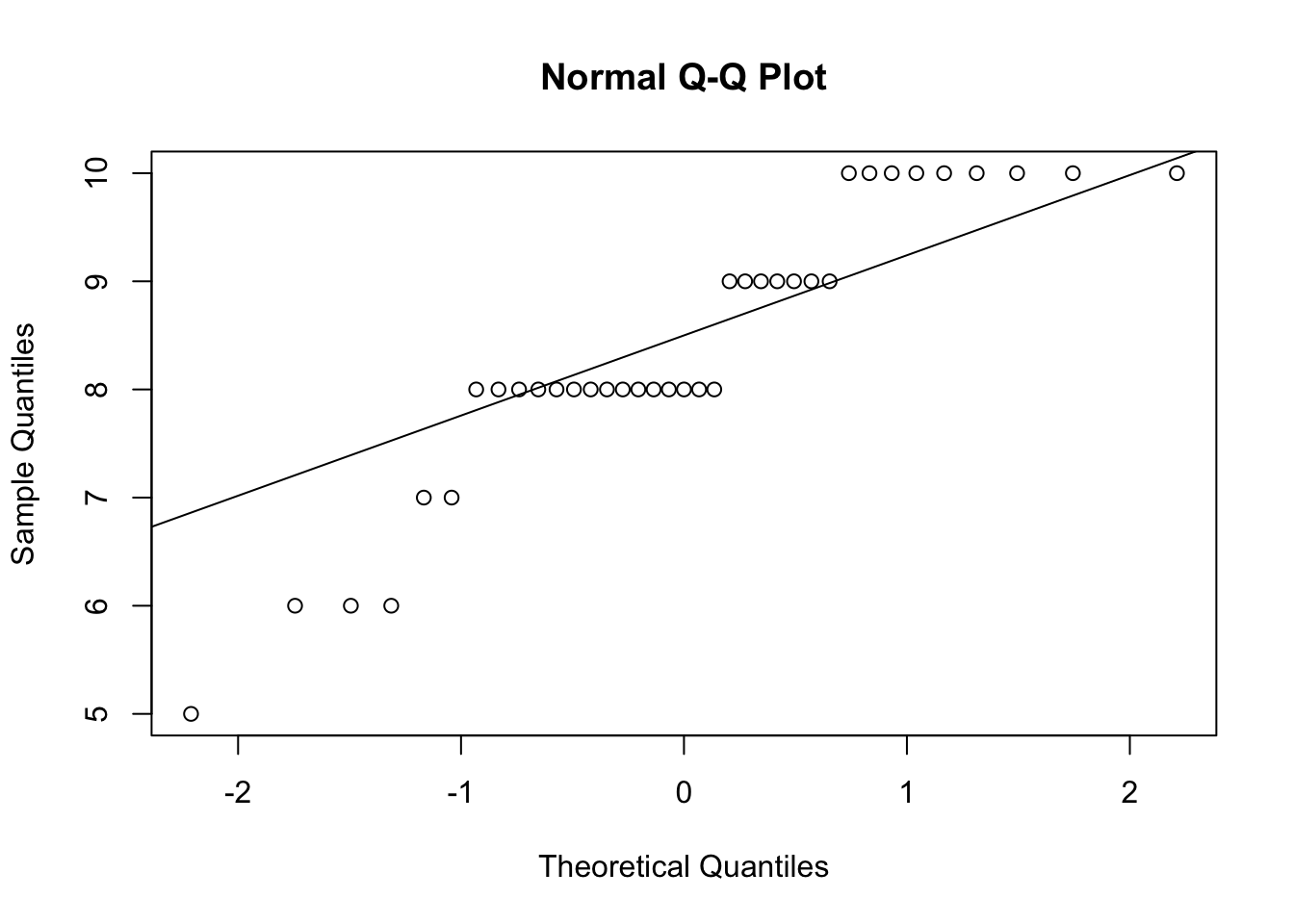
Erstelle sogenannte QQ Plots und führe den Shapiro Test auf Normalverteilung durch
# QQ-Plots für die vier Spalten erstellenqqnorm(psychologieExperiment$Gefuehl_Vor_SelberGutesTun)qqline(psychologieExperiment$Gefuehl_Vor_SelberGutesTun)
# Shapiro-Wilk-Test für die Normalverteilung durchführenshapiro_test_vor_selber <-shapiro.test(psychologieExperiment$Gefuehl_Vor_SelberGutesTun)shapiro_test_nach_selber <-shapiro.test(psychologieExperiment$Gefuehl_Nach_SelberGutesTun)shapiro_test_vor_anderen <-shapiro.test(psychologieExperiment$Gefuehl_Vor_AnderenGutesTun)shapiro_test_nach_anderen <-shapiro.test(psychologieExperiment$Gefuehl_Nach_AnderenGutesTun)# Shapiro-Wilk-Testergebnisse ausgebenshapiro_test_vor_selber
Shapiro-Wilk normality test
data: psychologieExperiment$Gefuehl_Vor_SelberGutesTun
W = 0.94075, p-value = 0.04874
shapiro_test_nach_selber
Shapiro-Wilk normality test
data: psychologieExperiment$Gefuehl_Nach_SelberGutesTun
W = 0.88499, p-value = 0.001157
shapiro_test_vor_anderen
Shapiro-Wilk normality test
data: psychologieExperiment$Gefuehl_Vor_AnderenGutesTun
W = 0.93818, p-value = 0.0404
shapiro_test_nach_anderen
Shapiro-Wilk normality test
data: psychologieExperiment$Gefuehl_Nach_AnderenGutesTun
W = 0.8824, p-value = 0.0009906
Sind alle Daten normalverteilt?
Die Ergebnisse des Shapiro-Wilk-Tests zeigen, dass der p-Wert für alle vier Variablen unter 0.05 liegt:
Gefühl Vor Selber Gutes Tun: p-Wert = 0.0487385
Gefühl Nach Selber Gutes Tun: p-Wert = 0.0011574
Gefühl Vor Anderen Gutes Tun: p-Wert = 0.0404011
Gefühl Nach Anderen Gutes Tun: p-Wert = 9.9057037^{-4}
Da alle p-Werte unter 0.05 liegen, können wir die Nullhypothese der Normalverteilung für alle Variablen ablehnen.
Antwort: Nein, die Daten sind nicht normalverteilt.
Beim t-Test hatten wir Gleichheit der Varianzen angenommen. Testet hier, ob diese Annahme korrekt war?
library(car) # Für den Levene-Test
Loading required package: carData
# Levene-Test für Gleichheit der Varianzenlevene_test_result <-leveneTest(c(psychologieExperiment$Gefuehl_Nach_SelberGutesTun, psychologieExperiment$Gefuehl_Vor_SelberGutesTun),group =rep(c("Nach", "Vor"), each =nrow(psychologieExperiment)))
Warning in
leveneTest.default(c(psychologieExperiment$Gefuehl_Nach_SelberGutesTun, :
rep(c("Nach", "Vor"), each = nrow(psychologieExperiment)) coerced to factor.
# Ausgabe des Testergebnissesprint(levene_test_result)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 0.0147 0.9039
72
pWertLevene <- levene_test_result$`Pr(>F)`[1]
ANTWORT:
Die Ausgabe des Levene-Tests zeigt Folgendes:
p-Wert des Levene-Tests: 0.9039338
Interpretation:
Der p-Wert ist deutlich grösser als 0.05, was darauf hindeutet, dass die Nullhypothese der Gleichheit der Varianzen nicht abgelehnt wird. Das bedeutet, dass es keinen statistisch signifikanten Unterschied in den Varianzen der Gruppen gibt.
Antwort: Ja, die Annahme der Gleichheit der Varianzen beim t-Test war korrekt.
Wie stark verändert sich der Median in den beiden Experimenten von Bevor zu Danach?
# Berechnung der Mediane für die Bedingungenmedian_vor_selber <-median(psychologieExperiment$Gefuehl_Vor_SelberGutesTun, na.rm =TRUE)median_nach_selber <-median(psychologieExperiment$Gefuehl_Nach_SelberGutesTun, na.rm =TRUE)median_vor_anderen <-median(psychologieExperiment$Gefuehl_Vor_AnderenGutesTun, na.rm =TRUE)median_nach_anderen <-median(psychologieExperiment$Gefuehl_Nach_AnderenGutesTun, na.rm =TRUE)# Berechnung der Veränderungen der Medianediff_median_selber <- median_nach_selber - median_vor_selberdiff_median_anderen <- median_nach_anderen - median_vor_anderen# Ausgabe der Ergebnissecat("Veränderung des Medians für Selber Gutes Tun:", diff_median_selber, "\n")
Veränderung des Medians für Selber Gutes Tun: 2
cat("Veränderung des Medians für Anderen Gutes Tun:", diff_median_anderen, "\n")
Veränderung des Medians für Anderen Gutes Tun: 2
ANTWORT:
Suche mit Entscheidungsbäumen, Chatbots, Internetsuche, etc. welcher statistische Test sich zum Vergleich der zentralen Tendenz dieser Daten eignet? ANTWORT: Wilcoxon-Vorzeichen-Rang-Test. Dieser vergleicht die Mediane von zwei abhängigen Stichproben.
Parameterfreier Tests, d.h. unabhängig von Verteilung der Daten
# Wilcoxon-Vorzeichen-Rang-Tests für beide Experimentewilcox_test_selber <-wilcox.test( psychologieExperiment$Gefuehl_Vor_SelberGutesTun, psychologieExperiment$Gefuehl_Nach_SelberGutesTun,paired =TRUE)
Warning in
wilcox.test.default(psychologieExperiment$Gefuehl_Vor_SelberGutesTun, : cannot
compute exact p-value with ties
Warning in
wilcox.test.default(psychologieExperiment$Gefuehl_Vor_SelberGutesTun, : cannot
compute exact p-value with zeroes
Warning in
wilcox.test.default(psychologieExperiment$Gefuehl_Vor_AnderenGutesTun, : cannot
compute exact p-value with ties
Warning in
wilcox.test.default(psychologieExperiment$Gefuehl_Vor_AnderenGutesTun, : cannot
compute exact p-value with zeroes
# Ausgabe der Testergebnissewilcox_test_selber
Wilcoxon signed rank test with continuity correction
data: psychologieExperiment$Gefuehl_Vor_SelberGutesTun and psychologieExperiment$Gefuehl_Nach_SelberGutesTun
V = 0, p-value = 2.768e-07
alternative hypothesis: true location shift is not equal to 0
wilcox_test_anderen
Wilcoxon signed rank test with continuity correction
data: psychologieExperiment$Gefuehl_Vor_AnderenGutesTun and psychologieExperiment$Gefuehl_Nach_AnderenGutesTun
V = 28, p-value = 2.051e-06
alternative hypothesis: true location shift is not equal to 0
Wie interpretierst du die Tests?
E.3.1 Interpretation der Warnungen und Testergebnisse:
E.3.1.1 Testergebnisse:
Wilcoxon-Test für Selber Gutes Tun:
V-Wert: 0
p-Wert: 2.7683169^{-7}
Der p-Wert ist viel kleiner als 0.05, was bedeutet, dass die Veränderung der Mediane statistisch signifikant ist. Die Nullhypothese (kein Unterschied der zentralen Tendenz) kann abgelehnt werden, was darauf hinweist, dass das Experiment „Selber Gutes Tun“ eine signifikante Veränderung im Median bewirkt hat.
Wilcoxon-Test für Anderen Gutes Tun:
V-Wert: 28
p-Wert: 2.0506755^{-6}
Auch hier ist der p-Wert viel kleiner als 0.05. Die Nullhypothese kann abgelehnt werden, was zeigt, dass auch das Experiment „Anderen Gutes Tun“ eine signifikante Veränderung im Median bewirkt hat.
E.3.2 Gesamtfazit:
Beide Experimente zeigen eine signifikante Veränderung der Mediane von „Bevor“ zu „Danach“. Die zentralen Tendenzen sind in beiden Fällen signifikant unterschiedlich. Dies unterstützt die Schlussfolgerung, dass die Handlung, sich selbst oder anderen etwas Gutes zu tun, eine positive Wirkung auf die Bewertung des Gefühls hat.